热活化延迟荧光材料(TADF)性质预测¶
Note
- 开始训练、评估前,请先确保性质数据文件(.dat)和SMILES(smis.txt)数据文件的存在,并对应修改 yaml 配置文件中的
data_dir为性质数据文件路径,sim_dir为SMILES数据文件路径。 - 开始训练、评估前,请安装
rdkit等,相关依赖请执行pip install -r requirements.txt安装。
| 预训练模型 | 指标 |
|---|---|
| Est.pdparams | loss(MAE): 0.045 |
| f.pdparams | loss(MAE): 0.036 |
| angle.pdparams | loss(MAE): 0.041 |
# Est 预测:
cd TADF_Est
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/Est/Est.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python Est.py mode=train
# f 预测:
cd TADF_f
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/f/f.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python f.py mode=train
# angle 预测:
cd TADF_angle
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/angle/angle.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python angle.py mode=train
# Est 评估:
cd TADF_Est
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/Est/Est.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python Est.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/TADF/Est/Est_model.pdparams
# f 评估:
cd TADF_f
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/f/f.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python f.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/TADF/f/f_model.pdparams
# angle 评估:
cd TADF_angle
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/f/f.dat https://paddle-org.bj.bcebos.com/paddlescience/datasets/TADF/smis.txt
python angle.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/TADF/angle/angle_model.pdparams
1. 背景简介¶
有机发光二极管(OLED)具有高效率、结构灵活和低成本的优势,在先进显示和照明技术中受到广泛关注。在有机发光二极管器件中,电注入载流子以1:3的比例形成单线态和三线态激子。以纯荧光材料为发光材料构建的OLED发光效率IQE理论极限为25%。另一方面,有机金属复合物发光材料通过引入稀有金属(Ir,Pt等)带来强自旋轨道耦合(SOC),可以将单线态激子通过系间窜越过程转化成三线态激子,从而利用三线态激子发出磷光,其IQE可达100%,但是稀有金属价格昂贵,为推广使用带来了阻碍。热活化延迟荧光材料(TADF)为解决这些问题提供了新思路,并引起了广泛关注。在TADF中,三线态通过逆系间窜越过程(RISC)转化成单重态并发出荧光,从而实现100%的IQE,而RISC过程很大程度上取决于最低单线态(S1)和最低三线态(T1) 之间的能隙( \(\Delta Est\) )。根据量子力学理论,ΔEST相当于HOMO和LUMO之间的交换积分的两倍。因此TADF分子的常见设计策略是将电子供体(D)和电子受体(A)以明显扭曲的二面角结合以实现HOMO和LUMO在空间上明显的分离。然而,与 \(\Delta Est\) 相反,振子强度( \(f\) )需要较大的HOMO和LUMO之间的重叠积分,这二者之间的矛盾需要进一步平衡。
2. 模型原理¶
通过高通量计算构建数据集,通过分子结构输入、指纹特征提取、特征降维三个环节实现分子特征表征,随后通过多层非线性变换学习分子结构特征与TADF关键参数间的复杂映射关系,最终实现端到端的性质预测。
3. TADF性质预测模型的实现¶
本样例包括对化学分子的能隙( \(\Delta Est\) ),振子强度( \(f\) ),电子供体与电子受体间的二面角( \(angle\) )三项性质的预测,接下来将以二面角 \(angle\) 为例,开始讲解如何基于PaddleScience代码,实现对于TADF性质预测模型的构建、训练、测试和评估。案例的目录结构如下:
tadf/
├──TADF_angle/
│ ├── config/
│ │ └── angle.yaml
│ ├── angle_model.py
│ ├── angle.dat
│ ├── angle.py
│ └── smis.txt
├── TADF_Est/
│ └── ...
├── TADF_f/
│ └── ...
└── requirements.txt
3.1 数据集准备¶
我们选择常用的49个受体和50个受体以单键相连的方式进行组合,通过穷举所有可能的组合位点我们得到了44470个分子。通过MMFF94力场优化得到分子的初始结构。从44470个分子中随机提取5136个分子,在B3LYP/6-31G(d)水平下对5136个分子进行基态结构优化,采用TDDFT方法在基态构型下进行激发态性质计算。
本案例所用数据包括性质数据文件(例如angle.dat)和SMILES数据文件(smis.txt)。分子性质数据文件的每一行为一条分子性质;smis.txt的每一行为一个分子的 SMILES描述,即用一串字符把分子结构编码成线性字符串,以第一条数据数据为例
其中小写c 代表芳香碳,n 代表芳香氮,[nH] 代表带一个氢原子的芳香氮。数字 1、2、3 表示环的开闭标记:第一个 1 开启了一个环,遇到下一个 1 就闭合它。
在依据配置文件的信息逐行对性质数据文件和SMILES数据文件进行加载后,首先通过 rdkit.Chem.rdFingerprintGenerator 将分子的SMILES描述转换为 Morgan 指纹。Morgan指纹是一种分子结构的向量化描述,通过局部拓扑被编码为 hash 值,映射到2048位指纹位上。随后,使用PCA把2048维降到主成分保留99%方差的维度。用PaddleScience代码表示如下
3.2 约束构建¶
本研究采用监督学习,按照 PaddleScience 的API结构说明,采用内置的 SupervisedConstraint 构建监督约束。用 PaddleScience 代码表示如下
| examples/tadf/TADF_angle/angle_model.py | |
|---|---|
SupervisedConstraint 的第二个参数表示采用均方误差 MSELoss 作为损失函数,第三个参数表示约束条件的名字,方便后续对其索引。
3.3 模型构建¶
对于三个预测对象,设计了相同的深度神经网络,网络结构为含有两层隐藏层的神经网络,第一层隐藏层含有587个神经元,第二层隐藏层含有256个神经元,隐藏层之间加入Dropout。以 \(angle\) 预测为例,用 PaddleScience 代码表示如下
| examples/tadf/TADF_angle/angle_model.py | |
|---|---|
3.4 优化器构建¶
在本案例的angle性质预测中,训练器采用Adam优化器,学习率设置为0.01,weight_decay 设置为 1e-5,用 PaddleScience 代码表示如下
| examples/tadf/TADF_angle/angle_model.py | |
|---|---|
3.5 模型训练¶
完成上述设置之后,只需要将上述实例化的对象按顺序传递给ppsci.solver.Solver,然后启动训练即可。用PaddleScience 代码表示如下
| examples/tadf/TADF_angle/angle_model.py | |
|---|---|
4. 完整代码¶
| examples/tadf/TADF_angle/angle_model.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 | |
5. 结果展示¶
下图展示能隙( \(\Delta Est\) ),振子强度( \(f\) ),电子供体与电子受体间的二面角( \(angle\) )三项性质的模型预测结果。
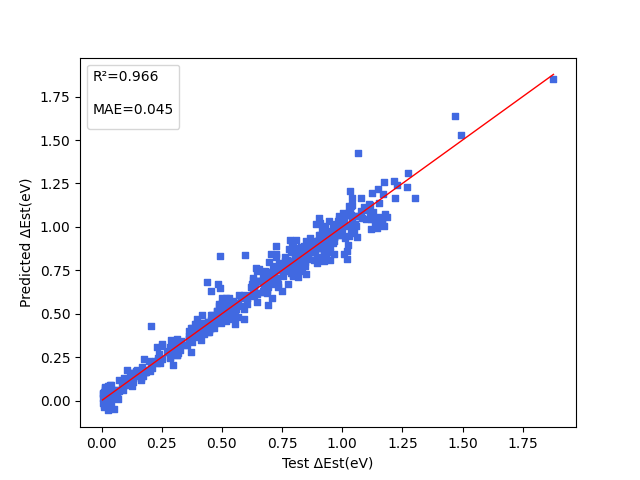
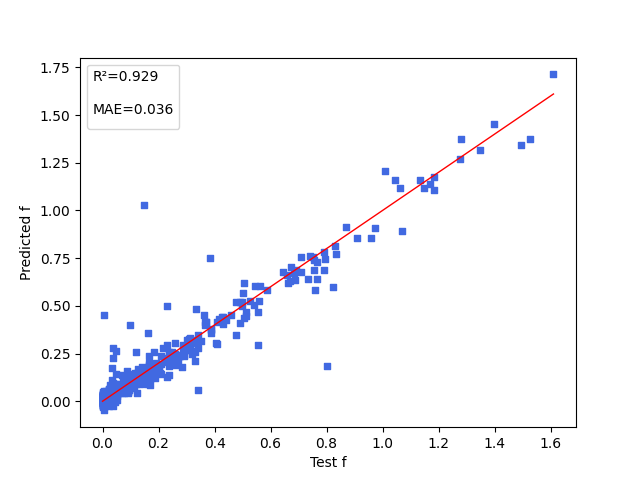
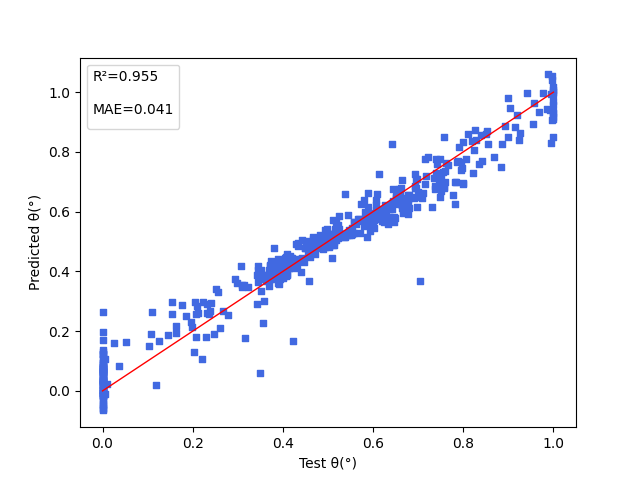
6. 参考文献¶
[1] Yufei Bu, Qian Peng*, Designing Promising Thermally Activated Delayed Fluroscence Emitters via Machine Learning-Assisted High-Throughput Virtual Screening. J. Phys. Chem. C. 2023. DOI: 10.1021/acs.jpcc.3c05337.