# set dataloader configdataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.TRAIN.dataset.anno,"preload":cfg.TRAIN.dataset.preload,"sample_ratio":cfg.TRAIN.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"sampler":{"name":"BatchSampler","shuffle":cfg.TRAIN.sampler.shuffle,"drop_last":cfg.TRAIN.sampler.drop_last,},"batch_size":cfg.TRAIN.batch_size,"use_shared_memory":cfg.TRAIN.use_shared_memory,"num_workers":cfg.TRAIN.num_workers,}
# model settingsMODEL:gen_net:input_keys:["data"]output_keys:["fake_image"]dim1:32dim2:64dim3:128dim4:256dim5:512sample_spatial:1.0dis_net:input_keys:["image"]output_keys:["score"]dim1:32dim2:64dim3:128dim4:256
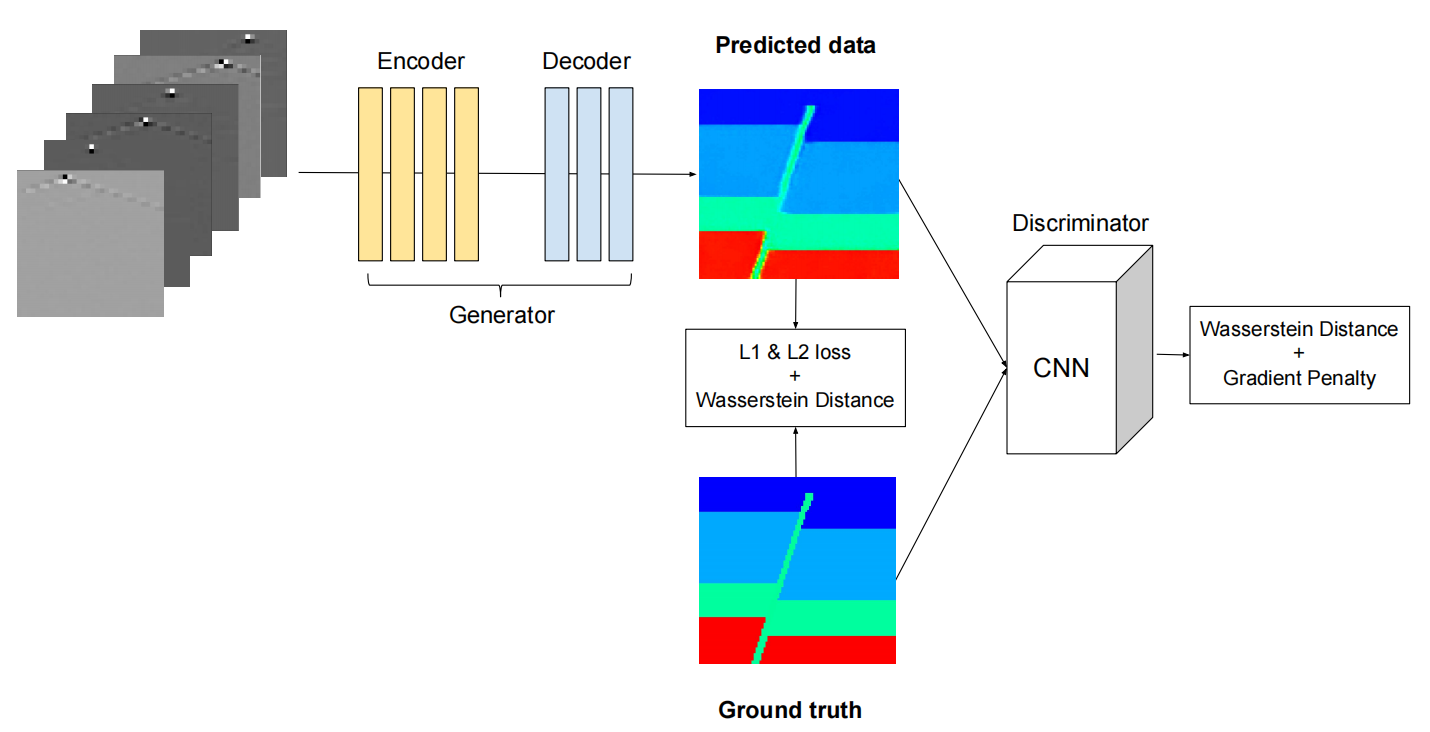
defloss_func_gen(self,output_dict,label_dict,*args):"""Calculate loss of generator. The loss includes L1 loss, L2 loss, and adversarial loss. Each of these losses has a corresponding weight, and if the weight of any loss is zero, it means that this loss component is not added during training. Args: output_dict: Output dict of model. label_dict: Label dict. Returns: Loss of generator. """l1loss=paddle.nn.L1Loss()l2loss=paddle.nn.MSELoss()pred=output_dict["fake_image"]label=label_dict["real_image"]loss_g1v=l1loss(pred,label)loss_g2v=l2loss(pred,label)loss=(self.weight["lambda_g1v"]*loss_g1v+self.weight["lambda_g2v"]*loss_g2v)loss_adv=-paddle.mean(self.model_dis({"image":pred})["score"])loss+=self.weight["lambda_adv"]*loss_advreturn{"loss_g":loss}
defloss_func_dis(self,output_dict,label_dict,*args):"""Calculate loss of discriminator. The discriminator's loss includes Wasserstein loss and gradient penalty, and only the gradient penalty has a weight parameter. Args: output_dict: Output dict of model. label_dict: Label dict. Returns: Loss of discriminator. """pred=output_dict["fake_image"]pred.stop_gradient=Truelabel=label_dict["real_image"]gradient_penalty=self.compute_gradient_penalty(label,pred)loss_real=paddle.mean(self.model_dis({"image":label})["score"])loss_fake=paddle.mean(self.model_dis({"image":pred})["score"])loss=-loss_real+loss_fake+gradient_penalty*self.weight["lambda_gp"]return{"loss_d":loss}defcompute_gradient_penalty(self,real_samples,fake_samples):"""Calculate the gradient penalty. Generate a random interpolation factor, create mixed samples, process through the discriminator, compute the gradient of the output, apply L2 norm and constrain it to 1, and finally obtain the gradient penalty. Args: real_samples: Ground truth data from dataset. fake_samples: Generated data from generator. Returns: Gradient penalty. """alpha=paddle.rand([real_samples.shape[0],1,1,1],dtype=real_samples.dtype)interpolates=alpha*real_samples+(1-alpha)*fake_samplesinterpolates.stop_gradient=False# Allow gradients to be calculatedd_interpolates=self.model_dis({"image":interpolates})["score"]gradients=paddle.grad(outputs=d_interpolates,inputs=interpolates,create_graph=True,retain_graph=True,only_inputs=True,)[0]gradients=gradients.reshape([gradients.shape[0],-1])gradient_penalty=paddle.mean((paddle.norm(gradients,p=2,axis=1)-1)**2)returngradient_penalty
# set constraintconstraint_gen=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(gen_funcs.loss_func_gen),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_gen",)constraint_gen_dict={constraint_gen.name:constraint_gen}constraint_dis=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(dis_funcs.loss_func_dis),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_dis",)constraint_dis_dict={constraint_dis.name:constraint_dis}
# set optimizeroptimizer=ppsci.optimizer.AdamW(learning_rate=cfg.TRAIN.learning_rate,weight_decay=cfg.TRAIN.weight_decay)optimizer_g=optimizer(model_gen)optimizer_d=optimizer(model_dis)
classSSIM(paddle.nn.Layer):""" SSIM is used to measure the similarity between two images. Attributes: window_size (int): The size of the gaussian window used for computing SSIM. Defaults to 11. size_average (bool): If True, the SSIM values across spatial dimensions are averaged. Defaults to True. Methods: forward(img1, img2): Computes the SSIM score between two images using a gaussian filter defined by `window`. """def__init__(self,window_size=11,size_average=True):super(SSIM,self).__init__()self.window_size=window_sizeself.size_average=size_averageself.channel=1self.window=create_window(window_size,self.channel)defforward(self,img1,img2):_,channel,_,_=img1.shapeifchannel==self.channelandself.window.dtype==img1.dtype:window=self.windowelse:window=create_window(self.window_size,channel)ifimg1.place.is_gpu_place():window=window.cuda(img1.place.gpu_device_id())window=window.astype(img1.dtype)self.window=windowself.channel=channelreturn_ssim(img1,img2,window,self.window_size,channel,self.size_average)defgaussian(window_size,sigma):gauss=paddle.to_tensor(data=[exp(-((x-window_size//2)**2)/float(2*sigma**2))forxinrange(window_size)],dtype="float32",)returngauss/gauss.sum()defcreate_window(window_size,channel):_1D_window=gaussian(window_size,1.5).unsqueeze(1)_2D_window=(paddle.mm(_1D_window,_1D_window.t()).astype("float32").unsqueeze(0).unsqueeze(0))window=_2D_window.expand([channel,1,window_size,window_size])returnwindowdef_ssim(img1,img2,window,window_size,channel,size_average=True):mu1=paddle.nn.functional.conv2d(x=img1,weight=window,padding=window_size//2,groups=channel)mu2=paddle.nn.functional.conv2d(x=img2,weight=window,padding=window_size//2,groups=channel)mu1_sq=mu1.pow(y=2)mu2_sq=mu2.pow(y=2)mu1_mu2=mu1*mu2sigma1_sq=(paddle.nn.functional.conv2d(x=img1*img1,weight=window,padding=window_size//2,groups=channel)-mu1_sq)sigma2_sq=(paddle.nn.functional.conv2d(x=img2*img2,weight=window,padding=window_size//2,groups=channel)-mu2_sq)sigma12=(paddle.nn.functional.conv2d(x=img1*img2,weight=window,padding=window_size//2,groups=channel)-mu1_mu2)C1=0.01**2C2=0.03**2ssim_map=((2*mu1_mu2+C1)*(2*sigma12+C2)/((mu1_sq+mu2_sq+C1)*(sigma1_sq+sigma2_sq+C2)))ifsize_average:returnssim_map.mean()else:returnssim_map.mean(axis=1).mean(axis=1).mean(axis=1)defssim_metirc(output_dict,label_dict):ssim_loss=SSIM(window_size=11)metric_dict={}forkeyinlabel_dict:ssim=ssim_loss(label_dict[key]/2+0.5,output_dict[key]/2+0.5)metric_dict[key]=ssimreturnmetric_dict
# set validatorvalidator=ppsci.validate.SupervisedValidator(dataloader_cfg=valid_dataloader_cfg,loss=ppsci.loss.MAELoss("mean"),output_expr={"real_image":lambdaout:out["fake_image"]},metric={"MAE":ppsci.metric.MAE(),"RMSE":ppsci.metric.RMSE(),"SSIM":ppsci.metric.FunctionalMetric(func_module.ssim_metirc),},name="val",)validator_dict={validator.name:validator}
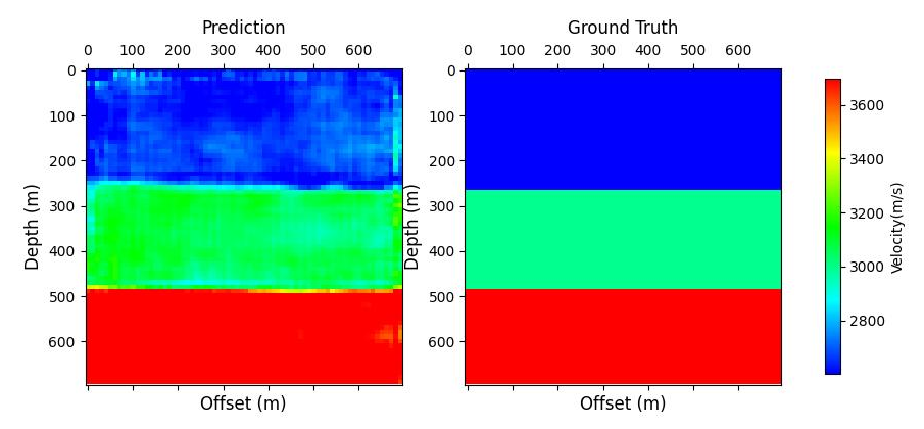
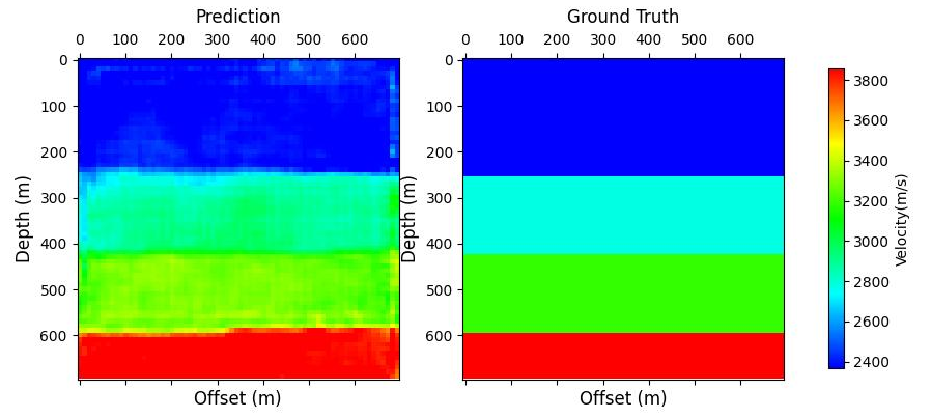
# visualizationifcfg.VIS.vis:withsolver.no_grad_context_manager(True):forbatch_idx,(input_,label_,_)inenumerate(validator.data_loader):ifbatch_idx+1>cfg.VIS.vb:breakfake_image=model_gen(input_)["fake_image"].numpy()real_image=label_["real_image"].numpy()foriinrange(cfg.VIS.vsa):plot_velocity(fake_image[i,0],real_image[i,0],f"{cfg.output_dir}/V_{batch_idx}_{i}.png",)print(f"The visualizations are saved to {cfg.output_dir}")
importjsonimportosimportsysimportfunctionsasfunc_moduleimporthydraimportpaddlefromfunctionsimportplot_velocityfromomegaconfimportDictConfigimportppscifromppsci.utilsimportloggeros.environ["FLAGS_embedding_deterministic"]="1"os.environ["FLAGS_cudnn_deterministic"]="1"os.environ["NVIDIA_TF32_OVERRIDE"]="0"os.environ["NCCL_ALGO"]="Tree"defevaluate(cfg:DictConfig):# get dataset configuration informationwithopen("dataset_config.json")asf:try:ctx=json.load(f)[cfg.DATASET]exceptKeyError:print("Unsupported dataset.")sys.exit()ifcfg.file_sizeisnotNone:ctx["file_size"]=cfg.file_size# get data transformationtransform_data,transform_label=func_module.create_transform(ctx,cfg.k)# set modelmodel_gen=ppsci.arch.VelocityGenerator(**cfg.MODEL.gen_net)# set valid_dataloader_cfgvalid_dataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.EVAL.dataset.anno,"preload":cfg.EVAL.dataset.preload,"sample_ratio":cfg.EVAL.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"batch_size":cfg.EVAL.batch_size,"use_shared_memory":cfg.EVAL.use_shared_memory,"num_workers":cfg.EVAL.num_workers,}# set validatorvalidator=ppsci.validate.SupervisedValidator(dataloader_cfg=valid_dataloader_cfg,loss=ppsci.loss.MAELoss("mean"),output_expr={"real_image":lambdaout:out["fake_image"]},metric={"MAE":ppsci.metric.MAE(),"RMSE":ppsci.metric.RMSE(),"SSIM":ppsci.metric.FunctionalMetric(func_module.ssim_metirc),},name="val",)validator_dict={validator.name:validator}# initialize solversolver=ppsci.solver.Solver(model=model_gen,validator=validator_dict,pretrained_model_path=cfg.EVAL.pretrained_model_path,)# evaluationsolver.eval()# visualizationifcfg.VIS.vis:withsolver.no_grad_context_manager(True):forbatch_idx,(input_,label_,_)inenumerate(validator.data_loader):ifbatch_idx+1>cfg.VIS.vb:breakfake_image=model_gen(input_)["fake_image"].numpy()real_image=label_["real_image"].numpy()foriinrange(cfg.VIS.vsa):plot_velocity(fake_image[i,0],real_image[i,0],f"{cfg.output_dir}/V_{batch_idx}_{i}.png",)print(f"The visualizations are saved to {cfg.output_dir}")deftrain(cfg:DictConfig):# get dataset configuration informationwithopen(cfg.DATASET_CONFIG)asf:try:ctx=json.load(f)[cfg.DATASET]exceptKeyError:print("Unsupported dataset.")sys.exit()ifcfg.file_sizeisnotNone:ctx["file_size"]=cfg.file_size# get data transformationtransform_data,transform_label=func_module.create_transform(ctx,cfg.k)# set modelmodel_gen=ppsci.arch.VelocityGenerator(**cfg.MODEL.gen_net)model_dis=ppsci.arch.VelocityDiscriminator(**cfg.MODEL.dis_net)# set class for loss functiongen_funcs=func_module.GenFuncs(model_dis,cfg.WEIGHT_DICT.gen)dis_funcs=func_module.DisFuncs(model_dis,cfg.WEIGHT_DICT.dis)# set dataloader configdataloader_cfg={"dataset":{"name":"FWIDataset","input_keys":("data",),"label_keys":("real_image",),"anno":cfg.TRAIN.dataset.anno,"preload":cfg.TRAIN.dataset.preload,"sample_ratio":cfg.TRAIN.dataset.sample_ratio,"file_size":ctx["file_size"],"transform_data":transform_data,"transform_label":transform_label,},"sampler":{"name":"BatchSampler","shuffle":cfg.TRAIN.sampler.shuffle,"drop_last":cfg.TRAIN.sampler.drop_last,},"batch_size":cfg.TRAIN.batch_size,"use_shared_memory":cfg.TRAIN.use_shared_memory,"num_workers":cfg.TRAIN.num_workers,}# set constraintconstraint_gen=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(gen_funcs.loss_func_gen),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_gen",)constraint_gen_dict={constraint_gen.name:constraint_gen}constraint_dis=ppsci.constraint.SupervisedConstraint(dataloader_cfg=dataloader_cfg,loss=ppsci.loss.FunctionalLoss(dis_funcs.loss_func_dis),output_expr={"fake_image":lambdaout:out["fake_image"]},name="cst_dis",)constraint_dis_dict={constraint_dis.name:constraint_dis}# set optimizeroptimizer=ppsci.optimizer.AdamW(learning_rate=cfg.TRAIN.learning_rate,weight_decay=cfg.TRAIN.weight_decay)optimizer_g=optimizer(model_gen)optimizer_d=optimizer(model_dis)# initialize solversolver_gen=ppsci.solver.Solver(model=model_gen,output_dir=cfg.output_dir,constraint=constraint_gen_dict,optimizer=optimizer_g,epochs=cfg.TRAIN.epochs_gen,iters_per_epoch=cfg.TRAIN.iters_per_epoch_gen,)solver_dis=ppsci.solver.Solver(model=model_gen,output_dir=cfg.output_dir,constraint=constraint_dis_dict,optimizer=optimizer_d,epochs=cfg.TRAIN.epochs_dis,iters_per_epoch=cfg.TRAIN.iters_per_epoch_dis,)# trainingforiinrange(cfg.TRAIN.epochs):logger.message(f"\nEpoch: {i+1}\n")solver_dis.train()solver_gen.train()# save model weightpaddle.save(model_gen.state_dict(),os.path.join(cfg.output_dir,"model_gen.pdparams"))@hydra.main(version_base=None,config_path="./conf",config_name="velocityGAN.yaml")defmain(cfg:DictConfig):ifcfg.mode=="train":train(cfg)elifcfg.mode=="eval":evaluate(cfg)else:raiseValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")if__name__=="__main__":main()