Suzuki-Miyaura 交叉偶联反应产率预测¶
Note
- 开始训练、评估前,请先下载数据文件data_set.xlsx,并对应修改 yaml 配置文件中的
data_dir为实际data_set.xlsx的文件路径。 - 如果需要使用预训练模型进行评估,请先下载预训练模型smc_reac_model.pdparams, 并对应修改 yaml 配置文件中的
load_model_path为模型参数路径。 - 首次训练、评估前,请执行
pip install -r requirements.txt安装rdkit等相关依赖。
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/SMCReac/data_set.xlsx
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/SMCReac/data_set.xlsx -o data_set.xlsx
python smc_reac.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/smc_reac/smc_reac_model.pdparams
1. 背景简介¶
Suzuki-Miyaura 交叉偶联反应表达式如下所示。
在零价钯配合物催化下,芳基或烯基硼酸或硼酸酯与氯、溴、碘代芳烃或烯烃发生交叉偶联。该反应具有反应条件温和、转化率高的优点,在材料合成、药物研发等领域具有重要作用,但存在开发周期长,试错成本高的问题。本研究通过使用高通量实验数据分析反应底物(包括亲电试剂和亲核试剂),催化配体,碱基,溶剂对偶联反应产率的影响,从而建立预测模型。
2. Suzuki-Miyaura 交叉偶联反应产率预测模型的实现¶
本节将讲解如何基于PaddleScience代码,实现对于 Suzuki-Miyaura 交叉偶联反应产率预测模型的构建、训练、测试和评估。案例的目录结构如下。
2.1 数据集构建和载入¶
本样例使用的数据来自参考文献[1]提供的开源数据,仅考虑试剂本身对于实验结果的影响,从中筛选了各分量均有试剂参与的部分反应数据,保存在文件 ./data_set.xlsx 中。该工作开发了一套基于流动化学(flow chemistry)的自动化平台,该平台在氩气保护的手套箱中组装,使用改良的高效液相色谱(HPLC)系统,结合自动化取样装置,从192个储液瓶中按设定程序吸取反应组分(亲电试剂、亲核试剂、催化剂、配体和碱),并注入流动载液中。每个反应段在温控反应盘管中以设定的流速、压力、时间进行反应,反应液通过UPLC-MS进行实时检测。通过调控亲电试剂、亲核试剂、11种配体、7种碱和4种溶剂的组合,最终实现了5760个反应条件的系统性筛选。接下来以其中一条数据为例结合代码说明数据集的构建与载入流程。
ClC=1C=C2C=CC=NC2=CC1 | CC=1C(=C2C=NN(C2=CC1)C1OCCCC1)B(O)O | C(C)(C)(C)P(C(C)(C)C)C(C)(C)C | [OH-].[Na+] | C(C)#N | 4.76
首先从表格文件中将实验材料信息和反应产率进行导入,并划分训练集和测试集,
| examples/smc_reac/smc_reac.py | |
|---|---|
应用 rdkit.Chem.rdFingerprintGenerator 将亲电试剂、亲核试剂、催化配体、碱和溶剂的SMILES描述转换为 Morgan 指纹。Morgan指纹是一种分子结构的向量化描述,通过局部拓扑被编码为 hash 值,映射到2048位指纹位上。用 PaddleScience 代码表示如下
2.2 约束构建¶
本案例采用监督学习,按照 PaddleScience 的API结构说明,采用内置的 SupervisedConstraint 构建监督约束。用 PaddleScience 代码表示如下
SupervisedConstraint 的第二个参数表示采用均方误差 MSELoss 作为损失函数,第三个参数表示约束条件的名字,方便后续对其索引。
2.3 模型构建¶
本案例设计了五条独立的子网络(全连接层+ReLU激活),每条子网络分别提取对应化学物质的特征。随后,这五个特征向量通过可训练的权重参数进行加权平均,实现不同化学成分对反应产率预测影响的自适应学习。最后,将融合后的特征输入到一个全连接层进行进一步映射,输出反应产率预测值。整个网络结构体现了对反应中各组成成分信息的独立提取与有权重的融合,符合反应机理特性。用 PaddleScience 代码表示如下
| ppsci/arch/smc_reac.py | |
|---|---|
7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 | |
模型依据配置文件信息进行实例化
| examples/smc_reac/smc_reac.py | |
|---|---|
参数通过配置文件进行设置如下
| examples/smc_reac/config/smc_reac.yaml | |
|---|---|
2.4 优化器构建¶
训练器采用Adam优化器,学习率设置由配置文件给出。用 PaddleScience 代码表示如下
| examples/smc_reac/smc_reac.py | |
|---|---|
2.5 模型训练¶
完成上述设置之后,只需要将上述实例化的对象按顺序传递给ppsci.solver.Solver,然后启动训练即可。用PaddleScience 代码表示如下
| examples/smc_reac/smc_reac.py | |
|---|---|
3. 完整代码¶
| examples/smc_reac/smc_reac.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 | |
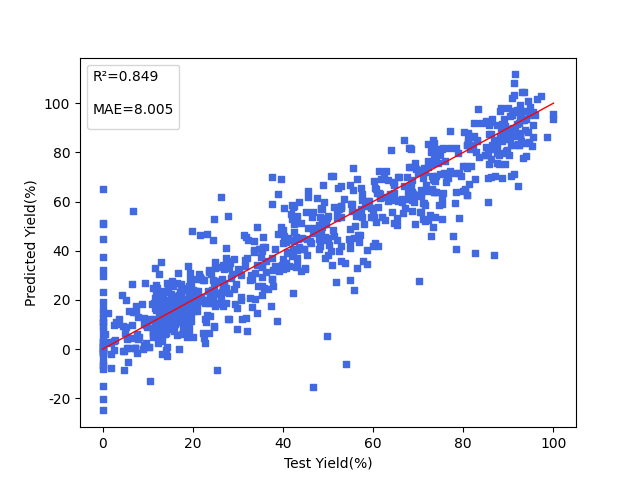
4. 结果展示¶
下图展示对 Suzuki-Miyaura 交叉偶联反应产率的模型预测结果。
5. 参考文献¶
[1] Perera D, Tucker J W, Brahmbhatt S, et al. A platform for automated nanomole-scale reaction screening and micromole-scale synthesis in flow[J]. Science, 2018, 359(6374): 429-434.