农作物种植情况实时监测¶
Note
运行模型前请在 PASTIS官网 中下载PASTIS数据集,并将其放在 ./UTAE/data/ 文件夹下。
# 语义分割任务
python train_semantic.py \
--dataset_folder "./data/PASTIS" \
--epochs 100 \
--batch_size 2 \
--num_workers 0 \
--display_step 10
# 全景分割任务
python train_panoptic.py \
--dataset_folder "./data/PASTIS" \
--epochs 100 \
--batch_size 2 \
--num_workers 0 \
--warmup 5 \
--l_shape 1 \
--display_step 10
# 语义分割任务
wget -c https://paddle-org.bj.bcebos.com/paddlescience/models/utae/semantic.pdparams -P ./pretrained/
python test_semantic.py \
--weight_file ./pretrained/semantic.pdparams \
--dataset_folder "./data/PASTIS" \
--device gpu
--num_workers 0
# 全景分割任务
wget -c https://paddle-org.bj.bcebos.com/paddlescience/models/utae/panoptic.pdparams -P ./pretrained/
python test_panoptic.py \
--weight_folder ./pretrained/panoptic.pdparams \
--dataset_folder ./data/PASTIS \
--batch_size 2 \
--num_workers 0 \
--device gpu
| 预训练模型 | 指标 |
|---|---|
| 语义分割任务 | OA (Over all Accuracy): 86.7% mIoU (mean Intersection over Union): 72.6% |
| 全景分割任务 | SQ (Segmentation Quality): 83.8 RQ (Recognition Quality): 58.9 PQ (Panoptic Quality): 49.7 |
背景简介¶
对农作物种植分布和生长状态进行高效、精准的监测,是现代智慧农业和粮食安全领域的核心需求。传统的人工勘察方法耗时费力,而利用单时相卫星影像进行分析的方法,难以应对云层遮挡问题,也无法捕捉作物在整个生长周期中的动态变化规律。
卫星图像时间序列(Satellite Image Time Series, SITS)技术为解决这一难题提供了新的途径。通过持续采集同一区域在不同时间的多光谱影像,SITS数据蕴含了作物从播种、出苗、生长、成熟到收割的全过程光谱和纹理信息。然而,SITS数据具有时序长、维度高、时空关联性强等特点,如何从中高效地提取特征并进行精确的像素级分类(语义分割)是一项重大的技术挑战。
本项目基于模型U-TAE(U-Net Temporal Attention Encoder),利用PaddlePaddle深度学习框架进行实现,旨在构建一个端到端的解决方案,对PASTIS数据集中的卫星影像时间序列进行语义分割,从而实现对多种农作物种植情况的自动化、高精度识别与监测。该技术可广泛应用于农业资源调查、产量预估、灾害评估等领域,具有重要的实用价值。
模型原理¶
本章节仅对U-TAE的模型原理进行简单介绍,详细的理论推导请参考论文:Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks
1. 整体结构¶
UTAE(U-Net Temporal Attention Encoder)采用编码器-解码器架构,专为卫星图像时间序列语义分割设计:
- 编码器:使用轻量化的ResNet-18,提取单时相的空间特征。
- 解码器:集成U-TAE模块,利用时间注意力机制聚合多时相的全局上下文信息。
- 输出:生成与输入相同分辨率的像素级类别概率图。
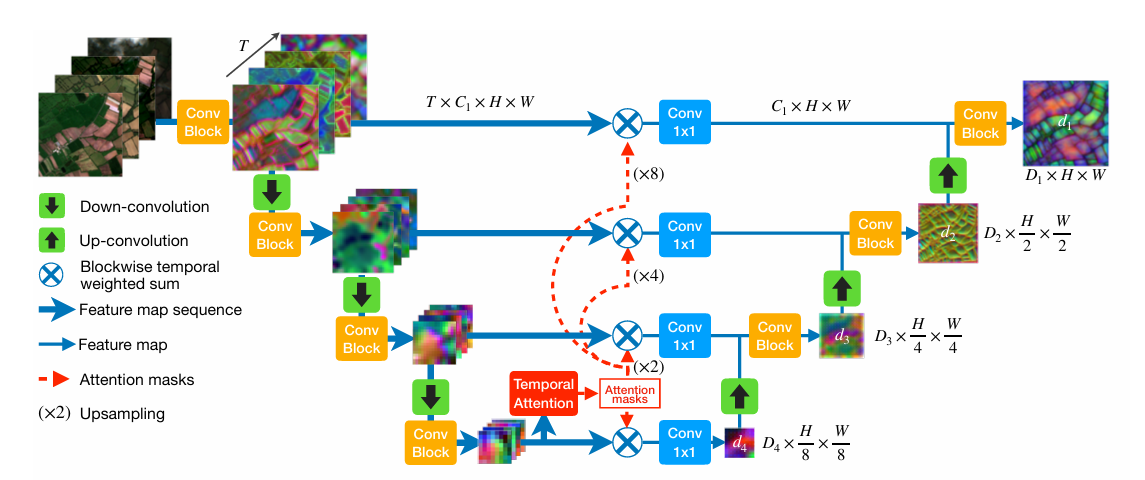
2. 时间注意力机制(Temporal Attention)¶
对于长度为 \(T\) 的帧序列,UTAE在解码阶段为每一帧计算帧间相似度权重,实现自适应的时序信息聚合:
- Query:当前帧的特征 \(\mathbf{Q}\)
- Key / Value:全部帧的特征 \(\mathbf{K}, \mathbf{V}\)
计算步骤如下:
然后,利用这些权重对全部帧的特征进行加权求和得到聚合特征:
该机制能自动抑制云层、阴影等低质量帧,提升作物边界的清晰度。
3. 全局-局部注意力块(GLTB)¶
每个解码器层包含两个并行分支:
-
全局分支:采用多头自注意力(Multi-Head Self-Attention)机制,建模田块级的长程依赖关系。
-
局部分支:使用 \(3 \times 3\) 深度可分离卷积,注重边缘和细节信息的保留。
两个分支的输出通过逐元素相加融合,既保持全局上下文,又保留局部纹理细节。
4. 实时推理优化¶
为实现高效实时推理,模型采用以下优化策略:
- 轻量级骨干:ResNet-18,参数量小于12M。
- 帧间共享权重:在同一序列中,Key和Value只计算一次,避免重复计算。
- 滑动窗口推理:将大图划分为多个块进行逐块推理,确保显存占用恒定。
数据集介绍¶
PASTIS数据集,该数据集由2433个 \(10\times128\times128\) 形状的多光谱图像序列组成。每个序列包含2018年9月至2019年11月之间的38至61个观察点,总计超过20亿像素。获取间隔时间不均匀,平均为5天。这种缺乏规律性的现象是由于卫星数据提供商对大量云层覆盖的采集进行了自动过滤。该数据集覆盖4000多平方公里,图像来自法国四个不同地区,气候和作物分布多样。 数据集可通过 PASTIS官网 下载。
模型实现¶
模型构建¶
本案例基于 UTAE(U-TAE) 实现,用 PaddleScience 封装如下:
| examples/UTAE/src/backbones/utae.py | |
|---|---|
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 | |
可视化结果¶
在 PASTIS 数据集上,本案例复现了全景分割预测与语义分割预测的可视化结果如图所示:
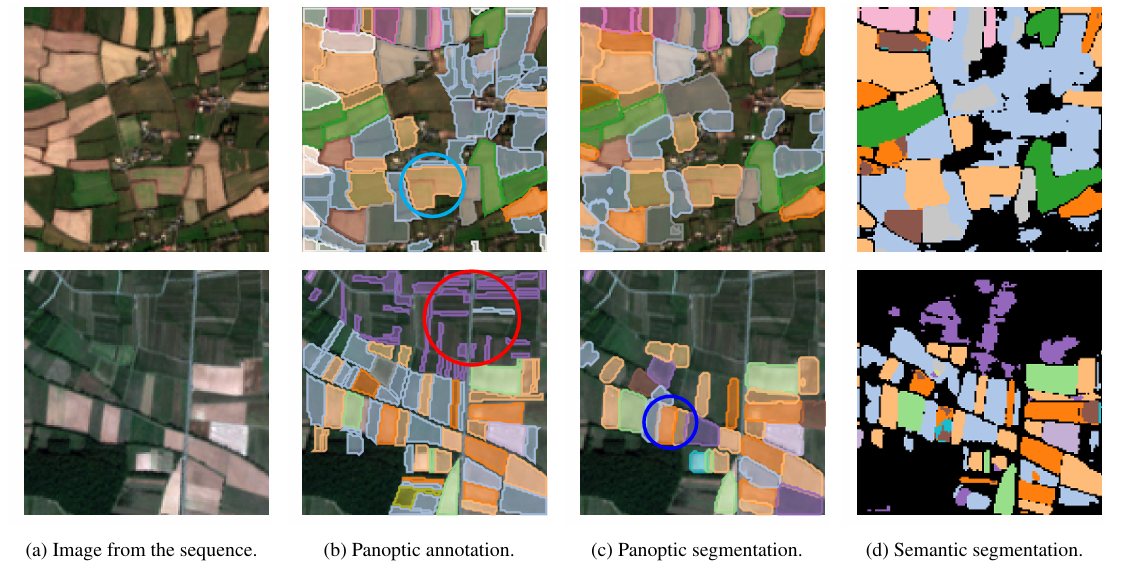
(a)原始图像 (b)标注(真实标签)(c) 全景分割预测 (d) 语义分割预测
上图展示了 PASTIS 数据集上的农田地块分割结果。在图中用不同颜色表示不同的地块。绿色圈出的位置代表大块地被错误识别为单一地块;红色圈出的位置代表很多细长地块未被正确检测;蓝色圈出的位置展示了 全景分割优于语义分割的情况。模型在区域边界检测方面具有较好表现,尤其在复杂边界的恢复上有所优势。但在面对细长、破碎或复杂地块时,仍然存在挑战,容易导致置信度下降或检测失败。