CGCNN (Crystal Graph Convolutional Neural Networks for an Accurate and Interpretable Prediction of Material Properties)¶
开始训练、评估前,请先下载数据集并进行划分。数据读取需要额外安装依赖 pymatgen,请运行安装命令 pip install pymatgen。
| 预训练模型 | 指标 |
|---|---|
| cgcnn_pretrained.pdparams | loss(MAE): 0.4195 |
1. 背景简介¶
机器学习方法在加速新材料设计方面变得越来越流行,其预测材料性质的精度接近于从头计算,但计算速度要快几个数量级。晶体系统的任意尺寸带来了挑战,因为它们需要表示为固定长度的向量,以便与大多数算法兼容。这个问题通常是通过使用简单的材料属性手动构造固定长度的特征向量或设计原子坐标的对称不变变换来解决的。然而,前者需要逐个设计来预测不同的性质,而后者由于复杂的变换使得模型难以解释。CGCNN是一个广义的晶体图卷积神经网络框架框架,用于表示周期性晶体系统,它既提供了具有密度泛函理论(DFT)精度的材料性质预测,又提供了原子水平的化学见解。因此本案例使用CGNN对二维半导体材料的能带性质进行预测。
2. 模型原理¶
本章节仅对 CGCNN 的模型原理进行简单地介绍,详细的理论推导请阅读 Crystal Graph Convolutional Neural Networks for an Accurate and Interpretable Prediction of Material Properties。
CGCNN 是一个用于表示周期性晶体系统的通用机器学习框架。与依赖人工构建特征向量的传统方法不同,CGCNN 直接在晶体图 (Crystal Graph) 之上构建卷积神经网络,从而自动学习表示,以达到密度泛函理论 (DFT) 的精度预测材料性质,并提供原子层级的化学见解。
晶体图表示 (Crystal Graph Representation):晶体结构转化为无向多重图 (Undirected Multigraph) \(G\)。 * 节点 (Nodes \(i\)): 代表原子。每个节点由一个特征向量 \(v_i\) 描述,编码了原子属性(如族数、周期数、电负性等)。 * 边 (Edges \((i,j)_k\)): 代表原子间的化学键连接。由于晶体的周期性,同一对原子之间可能存在多条边(多重图)。每条边由对应于连接原子 \(i\) 和 \(j\) 的第 \(k\) 个键的特征向量 \(u_{(i,j)_k}\) 定义。 * 构建方式: 通常在 6 Å 半径内搜索最近邻居。如果原子共享 Voronoi 面且距离足够近(基于共价键长度),则认为它们是连接的。
卷积层 (Convolutional Layers):核心的“学习”过程发生在卷积层。模型通过聚合周围原子和键的信息,迭代更新每个原子的特征向量,以捕捉局部化学环境。 卷积函数: 为了区分邻居之间相互作用强度的差异,模型使用了改进后的更新规则: $\(v_{i}^{(t+1)} = v_{i}^{(t)} + \sum_{j,k} \sigma(z_{(i,j)_{k}}^{(t)} W_{f}^{(t)} + b_{f}^{(t)}) \odot g(z_{(i,j)_{k}}^{(t)} W_{s}^{(t)} + b_{s}^{(t)})\)$ 其中: * 拼接 (\(z\)): \(z_{(i,j)_{k}}^{(t)} = v_{i}^{(t)} \oplus v_{j}^{(t)} \oplus u_{(i,j)_{k}}\) 是中心原子向量、邻居原子向量和键向量的拼接。 * 门控 (\(\sigma\)): Sigmoid 函数 \(\sigma(\cdot)\) 充当学习到的权重矩阵(即门控机制),用于自动区分不同邻居间相互作用的强度(例如自动忽略弱键)。 * 非线性 (\(g\)): 函数 \(g(\cdot)\) 增加了非线性耦合。 * 残差连接: 公式中加上原始的 \(v_{i}^{(t)}\) 使得训练更深层的网络变得更容易。
池化与输出 (Pooling and Output):经过 \(R\) 层卷积层后,模型需要生成一个代表整个晶体结构的固定长度向量,无论单元格中有多少个原子。 * 池化层 (Pooling Layer): 使用归一化求和 (Normalized Summation) 作为池化函数。 $\(v_{c} = \frac{1}{N} \sum_{i} v_{i}^{(R)}\)$ 这确保了表示具有原子索引排列不变性 (Permutational Invariance) 和晶胞大小不变性 (Size Invariance)。
- 输出层 (Output Layer): 晶体特征向量 \(v_c\) 通过全连接隐藏层 (\(L_1, L_2\)) 以捕捉复杂的映射关系,最后通过输出层预测目标属性 \(\hat{y}\)(例如形成能、带隙)。
模型的总体结构如图所示:
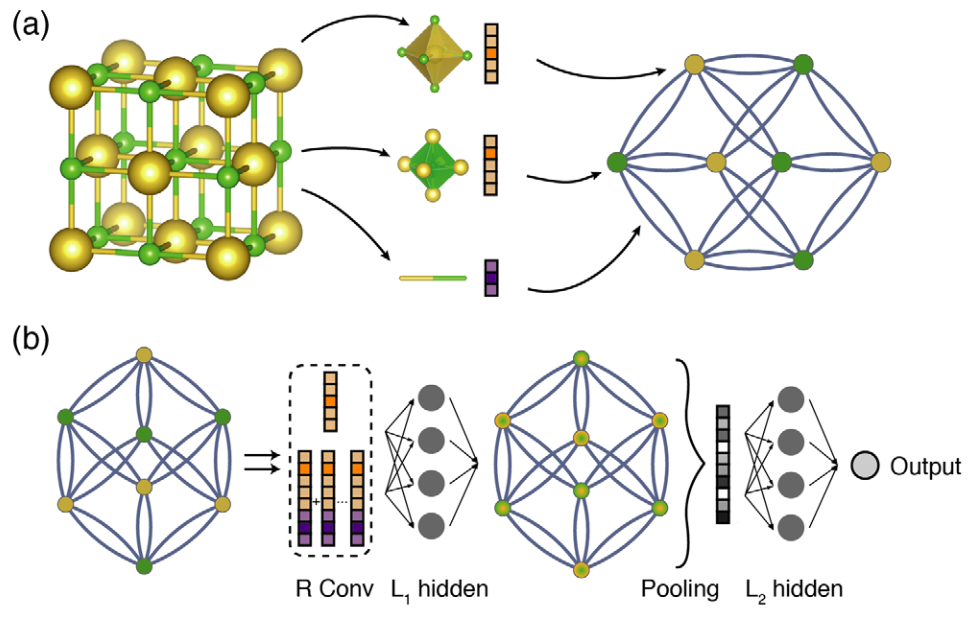
CGCNN 论文中预测了七种不同性质,接下来将介绍如何使用 PaddleScience 代码实现 CGCNN 网络预测二维半导体间隙性质
3.1 数据集介绍¶
CGCNN 原文中使用的是 数据集 (https://next-gen.materialsproject.org/) 和 数据集(https://cmr.fysik.dtu.dk/cubic_perovskites/cubic_perovskites.html)。
Materials Project 数据集由伯克利加州大学与劳伦斯伯克利国家实验室合作建立的大型开放式在线材料数据库,致力于提供全面的材料性能数据、结构信息和计算模拟结果。该数据集包含了来自高通量第一性原理计算的超过百万种无机材料的数据。其中包括晶体结构、能量特性、电子结构、热力学性质等详尽信息,为研究人员提供了丰富的材料数据资源。MPDataDoc对象共包含69个字段,其中57个字段分别从材料表示、光电性质、力学性质(弹性特性、剪切性质)、物理化学性质(化学组成、物理结构、微观结构)、稳定性和反应性(也属于化学性质)、热力学性质、磁性性质等方面描述材料的性质
本案例使用自行收集的数据集进行训练测试,如果用户需要使用本案例进行相关任务,可以参考以下数据集格式:
- CIF 用于记录用户所需的晶体结构的文件。
- [id _ prop.csv] 每个晶体的目标属性。
您可以通过创建一个目录root_dir来创建一个自定义数据集,该目录包含以下文件:
-
id_prop.csv: CSV 第一列为每个晶体重新编码一个唯一的ID,第二列重新编码目标属性的值。 -
atom_init.json: JSON 存储每个元素的初始向量。 -
ID.cif: CIF 对晶体结构进行重新编码的文件,其中ID是晶体在数据集中的唯一ID。
root_dir的结构应该是(root_dir泛指训练/评估/测试数据文件夹):
3.2 模型构建¶
CGCNN 需要通过所使用的数据进行模型构造,因此需要先实例化CGCNNDataset。在实例化CGCNNDataset后可以得到训练样本的长度和输入维度等信息,根据此信息和设定的模型超参数cfg.MODEL.atom_fea_len、cfg.MODEL.n_conv、cfg.MODEL.h_fea_len、cfg.MODEL.n_h完成CrystalGraphConvNet的实例化。
其中超参数cfg.MODEL.atom_fea_len、cfg.MODEL.n_conv、cfg.MODEL.h_fea_len、cfg.MODEL.n_h默认设定如下:
| examples/cgcnn/conf/CGCNN.yaml | |
|---|---|
3.3 约束构建¶
本问题模型为回归模型,采用监督学习方式进行训练,因此可以使用PaddleScience内置监督约束SupervisedConstraint构建监督约束。代码如下:
其中root_dir为训练集路径,batch_size为批训练大小。为了能够正常的批次训练,collate_fn需要根据模型进行重新设计。collate_pool代码如下:
3.4 评估器构建¶
为了实时监测模型的训练情况,我们将在每轮训练后对上一轮训练完毕的模型进行评估。与训练过程保持一致,我们使用PaddleScience内置的SupervisedValidator函数构建监督数据评估器。具体代码如下:
3.5 优化器构建¶
训练时使用SGD优化器进行训练,相关代码如下:
| examples/cgcnn/CGCNN.py | |
|---|---|
训练超参数cfg.TRAIN.lr、cfg.TRAIN.momentum、cfg.TRAIN.weight_decay等默认设定如下:
3.6 模型训练¶
由于本问题被建模为回归问题,因此可以使用PaddleScience内置的psci.loss.MAELoss('mean')作为训练过程的损失函数。同时选择使用随机梯度下降法对网络进行优化。并且将训练过程封装至PaddleScience内置的Solver中,具体代码如下:
| examples/cgcnn/CGCNN.py | |
|---|---|
4. 完整代码¶
| examples/cgcnn/CGCNN.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | |