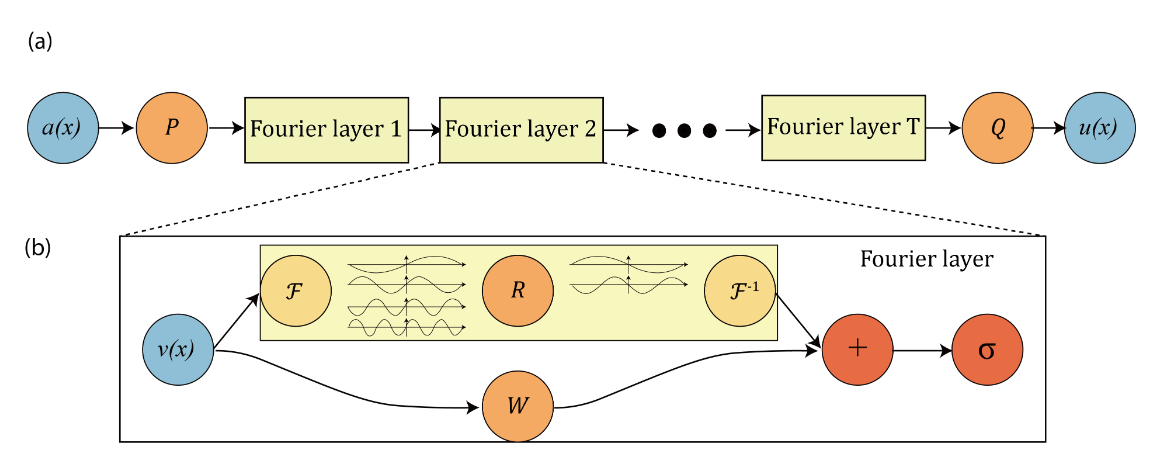
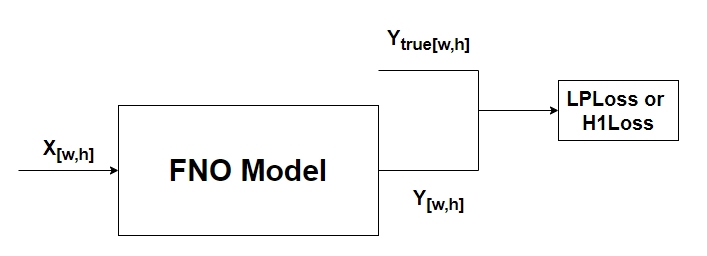
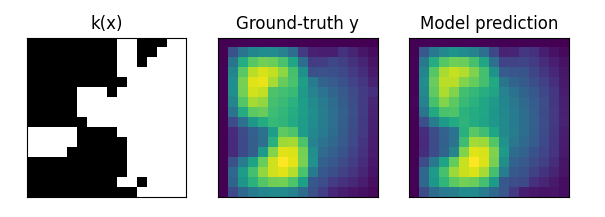
# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"train",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":0,}
# set lossl2loss=metric.LpLoss_train(d=2,p=2)h1loss=metric.H1Loss_train(d=2)ifcfg.TRAIN.training_loss=="l2":train_loss=l2lossifcfg.TRAIN.training_loss=="h1":train_loss=h1loss# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(train_loss),name="Sup",)constraint={sup_constraint.name:sup_constraint}
# model settingsMODEL:input_keys:["x"]output_keys:["y"]n_modes_height:16n_modes_width:16in_channels:3out_channels:1hidden_channels:32projection_channels:64n_layers:4use_mlp:Falsemlp:expansion:0.5dropout:0.0norm:"group_norm"fno_skip:"linear"mlp_skip:"soft-gating"separable:falsepreactivation:falsefactorization:"dense"rank:1.0joint_factorization:falsefixed_rank_modes:nullimplementation:"factorized"domain_padding:null#0.078125domain_padding_mode:"one-sided"#symmetricfft_norm:"forward"
# init optimizer and lr schedulerifcfg.TRAIN.lr_scheduler.type=="ReduceOnPlateau":lr_scheduler=paddle.optimizer.lr.ReduceOnPlateau(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,factor=cfg.TRAIN.lr_scheduler.gamma,patience=cfg.TRAIN.lr_scheduler.scheduler_patience,mode="min",)elifcfg.TRAIN.lr_scheduler.type=="CosineAnnealingDecay":lr_scheduler=paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,T_max=cfg.TRAIN.lr_scheduler.scheduler_T_max,)()elifcfg.TRAIN.lr_scheduler.type=="StepDecay":lr_scheduler=ppsci.optimizer.lr_scheduler.Step(epochs=cfg.TRAIN.lr_scheduler.epochs,iters_per_epoch=ITERS_PER_EPOCH,learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,step_size=cfg.TRAIN.lr_scheduler.step_size,gamma=cfg.TRAIN.lr_scheduler.gamma,)()else:raiseValueError(f"Got scheduler={cfg.TRAIN.lr_scheduler.type}")optimizer=ppsci.optimizer.Adam(lr_scheduler,weight_decay=cfg.TRAIN.wd)(model)
# set eval dataloader configeval_dataloader_cfg_16={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_16x16",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_32={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_32x32",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}h1_eval_metric=metric.H1Loss(d=2)l2_eval_metric=metric.LpLoss(d=2,p=2)sup_validator_16=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_16,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_16x16",)sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_32x32",)validator={sup_validator_16.name:sup_validator_16,sup_validator_32.name:sup_validator_32,}
# set eval dataloader configeval_dataloader_cfg_16={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_16x16",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_32={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_32x32",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}# set lossl2loss=metric.LpLoss_train(d=2,p=2)h1loss=metric.H1Loss_train(d=2)ifcfg.TRAIN.training_loss=="l2":train_loss=l2lossifcfg.TRAIN.training_loss=="h1":train_loss=h1lossh1_eval_metric=metric.H1Loss(d=2)l2_eval_metric=metric.LpLoss(d=2,p=2)sup_validator_16=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_16,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_16x16",)sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_32x32",)validator={sup_validator_16.name:sup_validator_16,sup_validator_32.name:sup_validator_32,}
# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"train",},"sampler":{"name":"BatchSampler","drop_last":True,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":0,}
# set lossl2loss=metric.LpLoss_train(d=2,p=2)h1loss=metric.H1Loss_train(d=2)ifcfg.TRAIN.training_loss=="l2":train_loss=l2lossifcfg.TRAIN.training_loss=="h1":train_loss=h1loss# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(train_loss),name="Sup",)constraint={sup_constraint.name:sup_constraint}
# model settingsMODEL:input_keys:["x"]output_keys:["y"]in_channels:3out_channels:1hidden_channels:64projection_channels:64n_layers:5uno_out_channels:[32,64,64,64,32]uno_n_modes:[[16,16],[8,8],[8,8],[8,8],[16,16]]uno_scalings:[[1.0,1.0],[0.5,0.5],[1,1],[2,2],[1,1]]horizontal_skips_map:nullincremental_n_modes:nulluse_mlp:falsemlp:expansion:0.5dropout:0.0norm:"group_norm"fno_skip:"linear"horizontal_skip:"linear"mlp_skip:"soft-gating"separable:falsepreactivation:falsefactorization:nullrank:1.0joint_factorization:falsefixed_rank_modes:nullimplementation:"factorized"domain_padding:0.2#0.078125domain_padding_mode:"one-sided"#symmetricfft_norm:"forward"
# init optimizer and lr schedulerifcfg.TRAIN.lr_scheduler.type=="ReduceOnPlateau":lr_scheduler=paddle.optimizer.lr.ReduceOnPlateau(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,factor=cfg.TRAIN.lr_scheduler.gamma,patience=cfg.TRAIN.lr_scheduler.scheduler_patience,mode="min",)elifcfg.TRAIN.lr_scheduler.type=="CosineAnnealingDecay":lr_scheduler=paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,T_max=cfg.TRAIN.lr_scheduler.scheduler_T_max,)()elifcfg.TRAIN.lr_scheduler.type=="StepDecay":lr_scheduler=ppsci.optimizer.lr_scheduler.Step(epochs=cfg.TRAIN.lr_scheduler.epochs,iters_per_epoch=ITERS_PER_EPOCH,learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,step_size=cfg.TRAIN.lr_scheduler.step_size,gamma=cfg.TRAIN.lr_scheduler.gamma,)()else:raiseValueError(f"Got scheduler={cfg.TRAIN.lr_scheduler.type}")optimizer=ppsci.optimizer.Adam(lr_scheduler,weight_decay=cfg.TRAIN.wd)(model)
# set eval dataloader configeval_dataloader_cfg_16={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_16x16",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_32={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_32x32",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}h1_eval_metric=metric.H1Loss(d=2)l2_eval_metric=metric.LpLoss(d=2,p=2)sup_validator_16=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_16,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_16x16",)sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_32x32",)validator={sup_validator_16.name:sup_validator_16,sup_validator_32.name:sup_validator_32,}
# set eval dataloader configeval_dataloader_cfg_16={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_16x16",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_32={"dataset":{"name":"DarcyFlowDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"grid_boundaries":cfg.DATASET.grid_boundaries,"encode_input":cfg.DATASET.encode_input,"encode_output":cfg.DATASET.encode_output,"encoding":cfg.DATASET.encoding,"channel_dim":cfg.DATASET.channel_dim,"data_split":"test_32x32",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}# set lossl2loss=metric.LpLoss_train(d=2,p=2)h1loss=metric.H1Loss_train(d=2)ifcfg.TRAIN.training_loss=="l2":train_loss=l2lossifcfg.TRAIN.training_loss=="h1":train_loss=h1lossh1_eval_metric=metric.H1Loss(d=2)l2_eval_metric=metric.LpLoss(d=2,p=2)sup_validator_16=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_16,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_16x16",)sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"h1":ppsci.metric.FunctionalMetric(h1_eval_metric),"l2":ppsci.metric.FunctionalMetric(l2_eval_metric),},name="Sup_Validator_32x32",)validator={sup_validator_16.name:sup_validator_16,sup_validator_32.name:sup_validator_32,}
# set train dataloader configtrain_dataloader_cfg={"dataset":{"name":"SphericalSWEDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"data_split":"train",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":True,},"batch_size":cfg.TRAIN.batch_size,"num_workers":0,}
# set losstrain_loss=metric.LpLoss_train(d=2,p=2,reduce_dims=[0,1])# set constraintsup_constraint=ppsci.constraint.SupervisedConstraint(train_dataloader_cfg,loss=ppsci.loss.FunctionalLoss(train_loss),name="Sup",)constraint={sup_constraint.name:sup_constraint}
# model settingsMODEL:input_keys:["x"]output_keys:["y"]in_channels:3out_channels:3n_modes:[32,32]hidden_channels:32projection_channels:64n_layers:4use_mlp:falsemlp:expansion:0.5dropout:0.0norm:'group_norm'fno_skip:"linear"mlp_skip:"soft-gating"separable:falsepreactivation:falsefactorization:nullrank:1.0joint_factorization:falsefixed_rank_modes:nullimplementation:"factorized"domain_padding:null#0.078125domain_padding_mode:"one-sided"#symmetricfft_norm:'forward'
# init optimizer and lr schedulerifcfg.TRAIN.lr_scheduler.type=="ReduceOnPlateau":lr_scheduler=paddle.optimizer.lr.ReduceOnPlateau(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,factor=cfg.TRAIN.lr_scheduler.gamma,patience=cfg.TRAIN.lr_scheduler.scheduler_patience,mode="min",)elifcfg.TRAIN.lr_scheduler.type=="CosineAnnealingDecay":lr_scheduler=paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,T_max=cfg.TRAIN.lr_scheduler.scheduler_T_max,)()elifcfg.TRAIN.lr_scheduler.type=="StepDecay":lr_scheduler=ppsci.optimizer.lr_scheduler.Step(epochs=cfg.TRAIN.lr_scheduler.epochs,iters_per_epoch=ITERS_PER_EPOCH,learning_rate=cfg.TRAIN.lr_scheduler.learning_rate,step_size=cfg.TRAIN.lr_scheduler.step_size,gamma=cfg.TRAIN.lr_scheduler.gamma,)()else:raiseValueError(f"Got scheduler={cfg.TRAIN.lr_scheduler.type}")optimizer=ppsci.optimizer.Adam(lr_scheduler,weight_decay=cfg.TRAIN.wd)(model)
# set eval dataloader configeval_dataloader_cfg_32={"dataset":{"name":"SphericalSWEDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"data_split":"test_32x64",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_64={"dataset":{"name":"SphericalSWEDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"data_split":"test_64x128",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}l2_eval_metric=metric.LpLoss(d=2,p=2,reduce_dims=[0,1])sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"l2":ppsci.metric.FunctionalMetric(l2_eval_metric)},name="Sup_Validator_32x64",)sup_validator_64=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_64,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"l2":ppsci.metric.FunctionalMetric(l2_eval_metric)},name="Sup_Validator_64x128",)validator={sup_validator_32.name:sup_validator_32,sup_validator_64.name:sup_validator_64,}
# set eval dataloader configeval_dataloader_cfg_32={"dataset":{"name":"SphericalSWEDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"data_split":"test_32x64",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}eval_dataloader_cfg_64={"dataset":{"name":"SphericalSWEDataset","data_dir":cfg.FILE_PATH,"input_keys":cfg.MODEL.input_keys,"label_keys":cfg.DATASET.label_keys,"train_resolution":cfg.DATASET.train_resolution,"test_resolutions":cfg.DATASET.test_resolutions,"data_split":"test_64x128",},"sampler":{"name":"BatchSampler","drop_last":False,"shuffle":False,},"batch_size":cfg.EVAL.batch_size,"num_workers":0,}train_loss=metric.LpLoss_train(d=2,p=2,reduce_dims=[0,1])l2_eval_metric=metric.LpLoss(d=2,p=2,reduce_dims=[0,1])sup_validator_32=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_32,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"l2":ppsci.metric.FunctionalMetric(l2_eval_metric)},name="Sup_Validator_32x64",)sup_validator_64=ppsci.validate.SupervisedValidator(eval_dataloader_cfg_64,loss=ppsci.loss.FunctionalLoss(train_loss),metric={"l2":ppsci.metric.FunctionalMetric(l2_eval_metric)},name="Sup_Validator_64x128",)validator={sup_validator_32.name:sup_validator_32,sup_validator_64.name:sup_validator_64,}