A Transformer Model for Symbolic regression towards Scientific Discovery¶
# linux
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/transformer4sr/data_generated.tar.gz
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/transformer4sr/data_generated.tar.gz -o data_generated.tar.gz
# unzip it
tar -xzvf data_generated.tar.gz
python transformer4sr.py
# download srsd dataset from huggingface
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_easy/
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_medium/
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_hard/
# running
python transformer4sr.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/transformer4sr/transformer4sr_pretrained.pdparams
| 预训练模型 | 指标 |
|---|---|
| transformer4sr_pretrained.pdparams | Mean ZSS distance(srsd-feynman_easy): 0.658 +- 0.390 Hit rate(srsd-feynman_easy): 8/30 Mean ZSS distance(srsd-feynman_medium): 0.674 +- 0.331 Hit rate(srsd-feynman_medium): 8/37 Mean ZSS distance(srsd-feynman_hard): 0.737 +- 0.188 Hit rate(srsd-feynman_hard): 1/39 |
1. 背景简介¶
符号回归(SR)搜索最能描述数值数据集的数学表达式,它大致分为三类,即 GP-based SR(基于遗传编程的符号回归)、ML-based SR(基于机器学习的符号回归)、DL-based SR(基于深度学习的符号回归)。基于遗传编程的 SR 算法的计算成本通常很高,因此该案例使用了一种针对符号回归的新 Transformer 模型,并将最佳模型应用于 SRSD 数据集(科学发现数据集的符号回归)进行推理和测试。
2. 问题定义¶
作者提出了一种基于 Transformer 网络的 SR 模型,称为 Transformer4SR (A Transformer Model for Symbolic regression towards Scientific Discovery),该模型用于处理封闭库问题,将符号回归的预定义词汇用特定的方法转化为 tokens。在该案例中,输入数据通过程序生成,数据通过模型后得到输出结果,再将其转化回符号表示,最终得到数据的符号回归结果。
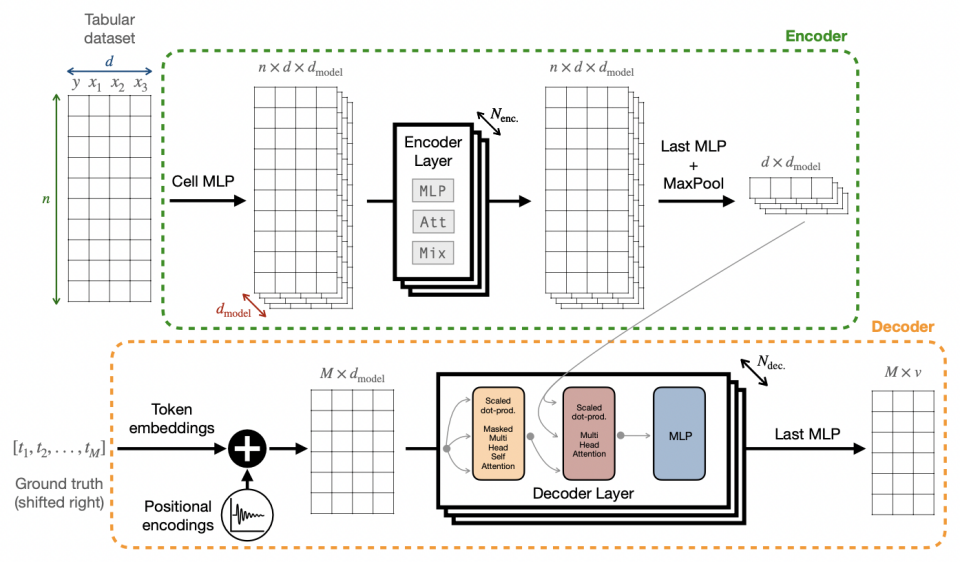
下图为该方法的网络结构图,该结构基于 Transformer 有编码器 Encoder 和解码器 Decoder 两个主要部分。 作者提出三种编码器架构:MLP、Att 或 Mix,在本案例中,主要实现了 Mix 下的编码器结构。解码器是标准的 Transformer 解码器。在训练期间,编码器接收表格数据集,解码器接收 tokens 的真实值序列,而在推理过程中,解码器是独立的,并以自动回归的方式预测 tokens。
3. 问题求解¶
接下来开始讲解如何将问题一步一步地转化为 PaddleScience 代码,用深度学习的方法求解该问题。 为了快速理解 PaddleScience,接下来仅对模型构建、方程构建、计算域构建等关键步骤进行阐述,而其余细节请参考 API文档。
3.1 数据集生成与下载¶
3.1.1 数据生成¶
该案例使用的训练数据为案例自主生成的数据:先用符号库中的符号随机生成大量公式;再通过一定的筛选机制筛除无效或不合规的公式;最后再根据这些公式进行采样;最终得到输入数据集和标签数据。
生成数据的参数信息如下:
其中num_init_trials为随机产生的初始方程数,这个值越大生成的数据越多,在原论文中这个值为 1000000。
设置相关参数后,可使用如下命令生成数据集:
3.1.2 数据下载¶
我们也提前生成了一个比原始训练数据规模小 10 倍的数据集(即num_init_trials为 100000),以便简单的进行模型训练,并提供了下载链接:
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/transformer4sr/data_generated.tar
tar -xvf data_generated.tar
该案例在开源符号回归数据集 SRSD(Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery) 上进行模型验证,因此需要预下载此数据集,该数据集存放在 huggingface 上,地址分别为srsd-feynman_easy、srsd-feynman_medium、srsd-feynman_hard。可从对应网页下载或使用 git 下载:
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_easy/
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_medium/
git clone https://huggingface.co/datasets/yoshitomo-matsubara/srsd-feynman_hard/
3.2 数据读取¶
由于数据读取和转换比较复杂,数据集相关的函数被定义在 functions_data.py 文件中,并在模型训练、验证等过程中被调用。
训练时需要读取自主生成的数据集:
验证时需要读取 SRSD 数据集:
数据相关参数定义在 yaml 文件中:
3.3 模型构建¶
在本问题中,我们使用神经网络 Transformer 作为模型。
为了在计算时,准确快速地访问具体变量的值,我们在这里指定网络模型的输入变量名是 ("input", "target_seq"),输出变量名是 ("output", ),这些命名与后续代码保持一致。
3.4 优化器构建¶
本案例使用一种自定义的学习率策略 LambdaDecay,该学习率策略支持自定义学习率衰减函数。训练过程会调用优化器来更新模型参数,此处选择较为常用的 Adam 优化器。
3.5 约束构建¶
在本案例中,我们使用监督数据集对模型进行训练,因此需要构建监督约束 SupervisedConstraint:
SupervisedConstraint 的第一个参数是监督约束的读取配置,其中 dataset 字段表示使用的训练数据集信息,各个字段分别表示:
name: 数据集类型,此处NamedArrayDataset表示数据集的类型为 Array;input: 输入数据;label: 标签数据;
batch_size 字段表示 batch的大小;
sampler 字段表示采样方法,其中各个字段表示:
name: 采样器类型,此处BatchSampler表示批采样器;drop_last: 是否需要丢弃最后无法凑整一个 mini-batch 的样本;shuffle: 是否需要在生成样本下标时打乱顺序;
第二个参数是损失函数,此处的 FunctionalLoss 为 PaddleScience 自定义 loss 函数类,该类支持编写代码时自定义 loss 的计算方法,loss 的具体实现为其参数 cross_entropy_loss_func, 这是一个被定义在 functions_loss_metric.py 文件中的函数,如下所示:
第三个参数是约束条件的名字,我们需要给每一个约束条件命名,方便后续对其索引。
在约束构建完毕之后,以我们刚才的命名为关键字,封装到一个字典中,方便后续访问:
3.6 评估器构建¶
在训练过程中通常会按一定轮数间隔,用验证集(测试集)评估当前模型的训练情况,因此使用 ppsci.validate.SupervisedValidator 构建评估器,构建过程与 约束构建 类似。
其中评估指标为自定义的指标计算函数 compute_inaccuracy,在 functions_loss_metric.py 文件中:
3.7 超参数设定¶
设置训练轮数等参数,如下所示。
3.8 模型训练、评估¶
完成上述设置之后,只需要将上述实例化的对象按顺序传递给 ppsci.solver.Solver,然后启动训练、评估。
3.9 模型验证与结果可视化¶
该案例在开源符号回归数据集 SRSD(Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery) 上进行模型验证,验证时采用自回归的方式运行解码器,不需要运行编码器。验证时的指标为一种基于树编辑距离的归一化指标 ZSS。
可视化的代码定义在文件 functions_vis.py 中,除了对验证集中的结果进行可视化外,还提供了一个公式为 \(25*x1+x2*log(x1)\) 的 demo 的可视化结果:
4. 完整代码¶
| transformer4sr.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 | |
5. 结果展示¶
下方展示了模型在公式 \(25*x1+x2*log(x1)\) 上的预测结果。

其中 \(C\) 表示常量,可以看到模型预测结果与真实公式基本一致。
6. 参考资料¶
@inproceedings{lalande2023,
title = {A Transformer Model for Symbolic Regression towards Scientific Discovery},
author = {Florian Lalande and Yoshitomo Matsubara and Naoya Chiba and Tatsunori Taniai and Ryo Igarashi and Yoshitaka Ushiku},
booktitle = {NeurIPS 2023 AI for Science Workshop},
year = {2023},
url = {https://openreview.net/forum?id=AIfqWNHKjo},
}