Identification of Pollution Sources (IOPS)¶
背景简介¶
随着城市化进程的加速和工业化的发展,空气污染成为全球面临的严重环境问题之一。污染物的来源复杂且多样,既包括工业排放、交通运输、燃煤等传统污染源,也有农业、建筑工地等其他潜在的污染源。这些污染物对人类健康、生态系统及气候变化造成了深远的影响。因此,准确识别污染源及其溯源,已成为环境保护和公共健康管理的重要课题。
污染源识别 是指通过监测数据、模型分析等手段,识别出空气污染的主要来源。传统的污染源识别方法往往依赖于单一的监测数据,如监测站点的污染物浓度数据,结合一定的物理化学模型进行推算。然而,单一的数据来源可能无法全面反映污染的复杂性,特别是在不同污染源交织的情况下,难以精确区分各个污染源的贡献。
污染源溯源(源解析)则是通过对空气污染物浓度的空间和时间分布进行分析,推断污染源的具体位置、排放强度及传播路径。污染源溯源技术通常结合环境监测、气象数据、化学物质的扩散模型以及大数据分析技术,进一步提升溯源的准确性与精确度。
近年来,随着高精度传感器、遥感技术、机器学习与大数据分析的快速发展,污染源识别与溯源研究得到了显著进展。通过多维度数据的融合(如 PM2.5、NO2、SO2、CO 等污染物浓度数据、气象数据、地理信息数据等),结合先进的人工智能算法,能够更准确地解析污染物的空间分布与来源特征。这些新兴技术不仅为政府和相关部门提供了有力的决策支持,也为污染防治政策的制定与优化提供了科学依据。
污染源识别与溯源的精确化,不仅有助于提升环境质量监控与治理的效果,还能够为环保政策的实施、污染控制措施的部署、以及污染事件的预警和应急响应提供重要的数据支持和科学指导。
1. 项目概述¶
本项目使用 PaddleScience 训练一个多层感知机(MLP)模型,来预测基于环境污染物浓度(PM2.5, PM10, SO2, NO2, CO)分类的污染类型。具体的流程包括数据预处理、模型构建、训练、评估和预测。
模型通过优化训练参数,使用类别权重平衡等机制、实现了95%+的分类准确率
2. 环境准备¶
2.1 安装依赖库¶
在开始之前,确保你已经安装了 PaddlePaddle 库。如果尚未安装,请通过以下命令安装:
2.2 数据准备¶
该项目的目标是基于环境污染物浓度预测污染类型。数据集格式如下:
| PM2.5 | PM10 | SO2 | NO2 | CO | Pollution Type |
|---|---|---|---|---|---|
| 28 | 52 | 3 | 46 | 0.5 | 偏粗颗粒型 |
| ... | ... | ... | ... | ... | ... |
数据保存在 .xlsx 文件中,包含五个污染物浓度字段(PM2.5, PM10, SO2, NO2, CO)以及污染类型标签。
3. 数据预处理¶
3.1 读取和处理数据¶
使用 Pandas 来读取 .xlsx 文件,并进行数据预处理,包括标签编码和特征标准化。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# 读取数据
df = pd.read_excel('./trainData.xlsx')
# 标签编码
label_encoder = LabelEncoder()
df['pollution_type'] = label_encoder.fit_transform(df['pollution_type'])
# 特征和标签
X = df[['PM2.5', 'PM10', 'SO2', 'NO2', 'CO']].values
y = df['pollution_type'].values
# 标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42, stratify=y)
3.2 特征标准化与标签编码¶
- 特征标准化:使用
StandardScaler对污染物浓度数据进行标准化,确保各特征在同一尺度上进行训练。 - 标签编码:使用
LabelEncoder将污染类型标签转换为数字,以便进行分类训练。
4. MLP 模型构建¶
我们使用 PaddleScience 的 MLP 类来定义多层感知机模型。
import paddlescience as ppsci
# 构建 MLP 模型
model = ppsci.arch.MLP(
input_keys=["input"], # 输入键
output_keys=["output"], # 输出键
input_dim=5, # 输入特征维度
output_dim=len(label_encoder.classes_), # 输出分类数
num_layers=3, # 网络层数
hidden_size=64, # 隐藏层单元数量
activation="ReLU" # 激活函数
)
4.1 模型参数说明¶
- input_dim:输入层维度,对应特征数。
- output_dim:输出层维度,对应分类数(污染类型的种类数)。
- num_layers:模型的层数,建议设置为 3 层。
- hidden_size:隐藏层神经元的数量,64 是常见的初始值。
- activation:激活函数,常用的有
"ReLU",此处使用ReLU激活函数。
5. 模型训练¶
5.1 设置训练参数¶
import paddle
import paddle.optimizer as optim
from sklearn.utils.class_weight import compute_class_weight
# 转换为 Paddle tensor
X_train_tensor = paddle.to_tensor(X_train, dtype='float32')
y_train_tensor = paddle.to_tensor(y_train, dtype='int64')
X_test_tensor = paddle.to_tensor(X_test, dtype='float32')
y_test_tensor = paddle.to_tensor(y_test, dtype='int64')
# 计算类别权重
class_weights = compute_class_weight('balanced', classes=np.unique(y), y=y)
class_weights_tensor = paddle.to_tensor(class_weights, dtype='float32')
# 损失函数(加入类别权重)
loss_fn = paddle.nn.CrossEntropyLoss(weight=class_weights_tensor)
# 优化器
optimizer = optim.Adam(parameters=model.parameters(), learning_rate=0.001)
5.2 训练过程¶
# 训练模型
epochs = 100
batch_size = 32
patience = 10
best_val_loss = float('inf')
early_stop_count = 0
for epoch in range(epochs):
model.train()
indices = np.random.permutation(len(X_train_tensor))
X_train_tensor = X_train_tensor[indices]
y_train_tensor = y_train_tensor[indices]
for i in range(0, len(X_train_tensor), batch_size):
X_batch = X_train_tensor[i:i+batch_size]
y_batch = y_train_tensor[i:i+batch_size]
# 前向传播
logits = model(X_batch)
loss = loss_fn(logits, y_batch)
# 反向传播和优化
loss.backward()
optimizer.step()
optimizer.clear_gradients()
# 验证阶段
model.eval()
with paddle.no_grad():
val_logits = model(X_test_tensor)
val_loss = loss_fn(val_logits, y_test_tensor).numpy()
val_predictions = paddle.argmax(val_logits, axis=1).numpy()
val_accuracy = np.mean(val_predictions == y_test)
print(f"Epoch [{epoch+1}/{epochs}], Train Loss: {loss.numpy():.4f}, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy * 100:.2f}%")
# 早停机制
if val_loss < best_val_loss:
best_val_loss = val_loss
early_stop_count = 0
paddle.save(model.state_dict(), 'best_model.pdparams')
else:
early_stop_count += 1
if early_stop_count > patience:
print("早停机制触发,停止训练")
break
5.3 早停机制¶
- 早停:用于避免模型在验证集上的过拟合,当验证损失不再下降时停止训练。
- 训练输出:每个 epoch 输出训练损失、验证损失和验证准确度。
6. 模型评估¶
6.1 加载最佳模型¶
6.2 测试集评估¶
# 测试集评估
model.eval()
with paddle.no_grad():
test_logits = model(X_test_tensor)
test_predictions = paddle.argmax(test_logits, axis=1).numpy()
# 分类报告
from sklearn.metrics import classification_report
print(classification_report(y_test, test_predictions, target_names=label_encoder.classes_))
- 分类报告:通过
classification_report输出每个类别的准确率、召回率和 F1 分数。
模型的损失曲线、准确率曲线与混淆矩阵如下:
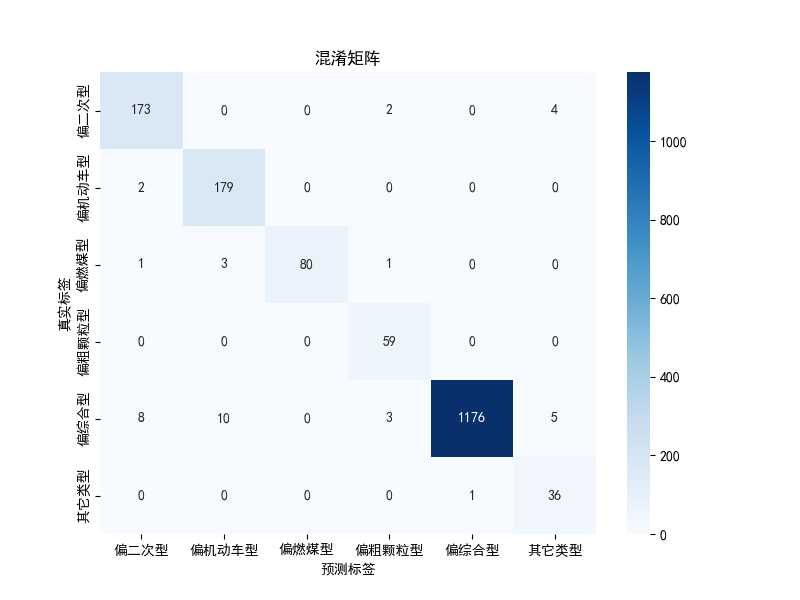
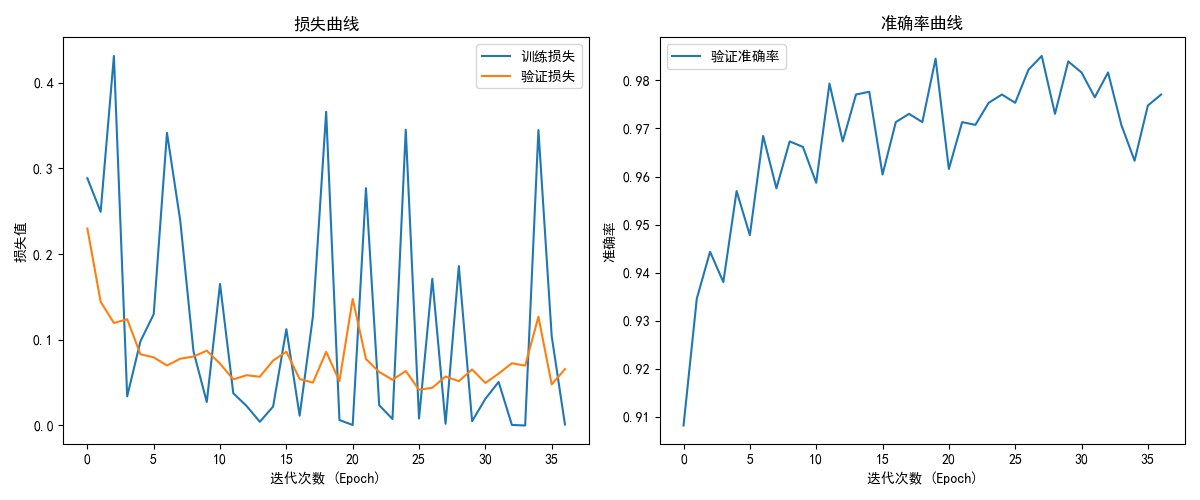
7. 模型保存与部署¶
7.1 保存模型参数¶
7.2 保存特征标准化器与标签编码器¶
import pickle
# 保存特征标准化器
with open('scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
# 保存标签编码器
with open('label_encoder.pkl', 'wb') as f:
pickle.dump(label_encoder, f)
7.3 加载模型和数据¶
# 加载模型参数
model.set_state_dict(paddle.load('pollution_model.pdparams'))
# 加载特征标准化器和标签编码器
with open('scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
with open('label_encoder.pkl', 'rb') as f:
label_encoder = pickle.load(f)
8. 测试样本预测¶
# 测试样本
test_sample = [[28, 52, 3, 46, 0.5]] # PM2.5, PM10, SO2, NO2, CO
# 标准化样本
test_sample_scaled = scaler.transform(test_sample)
# 转换为 Paddle tensor
test_sample_tensor = paddle.to_tensor(test_sample_scaled, dtype='float32')
# 模型预测
with paddle.no_grad():
prediction = model(test_sample_tensor)
predicted_class = paddle.argmax(prediction, axis
=1).numpy()[0]
# 显示预测结果
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
print(f"预测的污染类型为: {predicted_label}")
- 预测样本:使用标准化后的输入数据进行预测,并输出污染类型标签。