KMCast¶
开始训练、评估前,请下载数据集:
# GFS 数据
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/kmcast/GFS_all_spinup.nc -P ./dataset/
# WRF 数据
wget -c https://paddle-org.bj.bcebos.com/paddlescience/datasets/kmcast/WRF_all_spinup.nc -P ./dataset/
1 背景简介¶
随着全球风电装机容量的迅速扩张,风电从资源评估、机组控制到电网调度等环节,都在逐渐依赖高时空分辨率的气象信息。风速在海岸、岛屿及复杂地形区域往往受到海陆风环流、局地急流、山谷风、边界层结构等多种中小尺度过程的影响,这些过程决定着机组来流风的细节,也决定着风电场的功率稳定性和极端风风险。如果风速场过于平滑或偏差过大,就会直接导致发电量预测错误、调度策略不合理,或在长期规划中形成不正确的投资判断。因此,一个能够刻画公里级空间结构的风场对于风电行业至关重要。
然而,目前最常使用的天气和气候模式在分辨率上仍受到严重限制。全球预报模式(如 GFS)以及多项 AI 天气模式通常在 25 公里量级,这种尺度无法解析海岸线细节、地形突变、小型岛屿或海湾,因此不能表现真实存在的局地加速带、遮蔽尾迹和风速突变。气候模式的分辨率更为粗糙,往往在百公里量级,使得整个风电场甚至多个沿海站点在模式上表现得几乎一致,与真实世界的差异非常明显。模式无法显式模拟对流和湍流过程,而这些过程的参数化正是风速偏差与“场过于光滑”的重要来源。
为了获得更接近真实的风场结构,许多研究依赖区域数值模式(例如 WRF)的动力降尺度,通过更细的网格和显式对流来重建局地风场。这样的模拟确实能够显著改善风场结构和极端统计,但其计算成本极高。即便仅限于单一地区、每天模拟一次,其运算仍可能需要大量计算资源,这使得在实际风电运营中每日运行高分辨率模拟几乎不现实;在气候研究中对长时间序列进行公里级动力降尺度更是成本难以承受。
近年来,深度学习成为一种潜在的替代方案,通过学习高分辨率模拟的统计结构,将粗分辨率模式的输出“补充”成更精细的风场图像。但是现有的机器学习降尺度研究主要聚焦于降水、温度等变量,对于近地面风场尤其是海岸和复杂地形区域的风速精细结构关注较少。此外,大多数方法仍然将天气预报和气候模拟视为两个截然独立的任务,缺乏一种能够同时处理短期天气预测与长期气候分析的统一框架,也缺乏对风电行业最关心的极端风速、局地梯度和不确定性的系统刻画。
因此,本研究背景可归结为:在风电行业对公里级气象信息需求持续增加的形势下,传统预报模式分辨率不足、动力降尺度成本过高,而现有深度学习方法覆盖有限、缺乏统一的天气–气候框架。在这样的背景下,开发一种能够以极低成本生成可信的公里级风场、既服务短时预报又服务长期风气候评估的新方法变得十分迫切。KMCast 正是在这一需求缺口下提出的,通过生成式扩散模型学习高分辨率模拟的空间细节,以弥补粗分辨率模式的不足,同时建立一种贯通天气预报和气候模拟的统一方法体系。
2 模型原理¶
2.1 扩散模型¶
KMCast主要采用条件扩散模型,采用逐步去噪的方式,在低分辨率输入的条件下生成高分辨率图像。在前向扩散过程中,逐步向高分辨率图像中加入高斯噪声,经过多个时间步,图像逐渐转变为各向同性的噪声分布。通过以下随机过程,我们将目标分布 \(p(x_0)\) 转变为标准高斯噪声:
其中, \(x_t\) 是随时间变化的潜在变量,时间索引 \(t\) 取值范围为 \([0, T]\) ,超参数 \(\beta_t\) 随着时间步 \(t\) 递增,呈单调增长的趋势。
在逆向阶段,模型以低分辨率输入 \(y\) 为条件,利用U-Net架构逐步预测并去除噪声,通过梯度下降优化实现图像复原。\(\mu_\theta\) 和 \(\Sigma_\theta\) 分别为模型中可学习的均值向量和协方差矩阵,这些参数通过最大化变分下界(变分推断)对负对数似然的优化进行训练。逆向的条件概率表示为:
模型的损失函数定义为:
这一双向机制使得模型能够从纯噪声中逐步重建出高分辨率图像,同时保持图像的结构完整性。
2.2 网络架构与训练细节¶
为了在多尺度生成过程中保持模型的兼容性和稳定性,我们采用了UNet架构作为噪声预测器。该模型经过优化,增加了6个编码层和6个解码层。基本通道数设置为32,通道倍增方案为[1, 2, 4, 8, 8]。每一层包含两个残差块。整个UNet模型拥有约2300万参数。
输入数据在扩散训练过程中由14个粗分辨率的GFS通道组成。为了降低计算负担,同时保留关键气象特征,我们选择了从原始WRF输出数据中提取的代表性子区域。北哥伦比亚区域定义为经度77.5°W至69.5°W,纬度8°N至13.5°N;长江三角洲区域定义为经度117°E至123.5°E,纬度29°N至34.5°N。两个区域的空间尺寸均为192×256像素。模型输出的高分辨率风场包括东西向和南北向分量,空间尺寸与输入保持一致。
在训练过程中,采用Adam优化器,学习率设为 \(1\times 10^{-4}\) , \(\beta_1=0.9,\beta_2=0.999\) 。KMCast条件扩散模型在其网络架构中使用SiLU激活函数。为了防止过拟合,训练中采用了0.2的dropout率,并对训练数据进行随机打乱。此外, \(\beta_1\) 参数遵循线性调度,从 \(1\times 10^{-6}\) 开始,经过2000个时间步逐步增加至 \(1\times 10^{-2}\) 。模型在一台A100 GPU上训练了58万步,总批次大小为4,整个训练时间约为2天。
为气候预测目的,我们还训练了一个每日尺度的模型,用于适应气候模型的输出。该模型的架构与小时尺度模型相同,唯一的区别在于时间分辨率和输入仅包括东西向和南北向风分量,适用于5天预报。
2.3 评价指标¶
为了全面衡量模型预测的准确性和不确定性,我们采用了两项关键指标:平均绝对误差(MAE)和均方根误差(RMSE)。具体定义如下:
其中, \(\hat{x}_i\) 代表模型的预测值, \(x_i\) 为真实值, \(n\) 为样本数量。 KMCast模型整体架构如图所示:
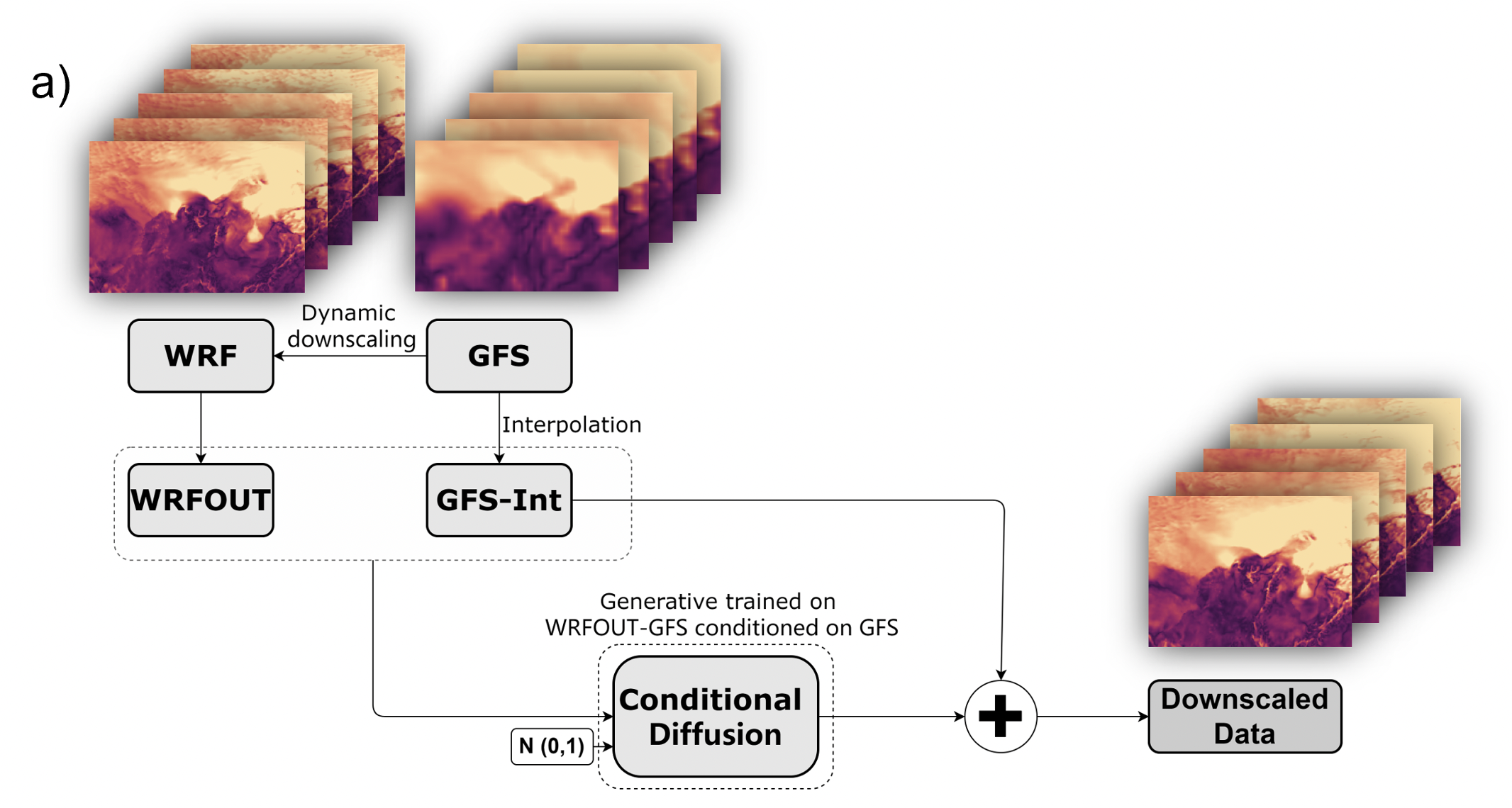
3 数据说明¶
3.1 观测数据集¶
在哥伦比亚地区,收集了来自四个气象站的观测数据:
- 阿尔米兰特·帕迪利亚(Almirante Padilla,东经-72.926°,北纬11.526°)
- 西蒙·玻利瓦尔(Simon Bolivar,东经-74.231°,北纬11.120°)
- 拉斐尔·努涅斯(Rafael Nunez,东经-75.513°,北纬10.442°)
- 欧内斯特·科尔蒂索斯(Ernesto Cortissoz,东经-74.781°,北纬10.890°)
所有站点提供2022年全年每小时的观测数据。
为了更好地评估长期模拟的性能,还在中国进行了补充验证。中国拥有更多的气象站点和更长的观测时间段。我们从中国日报气象要素站观测数据中获取了2008年至2018年的10米东西向(U分量)和南北向(V分量)风场数据,该数据由全国超过4000个气象站每日计算值组成。
用于哥伦比亚北部地区的GFS(全球预报系统)数据涵盖874天,每次初始化后可进行10天预报,时间分辨率为3小时(共81个预报步骤),每个预报中选择15个时间点,共计13,110个时刻。对于WRF(微尺度气象模型)数据,我们提取了相同的13,110个时间点,以确保与GFS数据的时间对齐。在模型训练和测试策略方面,最新的2,000个时间点用于测试,其余数据用于模型训练。
中国区域的WRF数据覆盖了334天,每个预报选择15个时间点,共计5,110个时间点,全部用于气候模型的训练。
输入数据集来自GFS,经过双线性插值处理,空间分辨率调整至3公里。我们采用每日0000 UTC启动的10天预报,空间分辨率为25公里,时间分辨率为3小时,覆盖2020年至2022年的全年数据。
用于千米尺度气候模拟的输入为FGOALS-f3-H的历史数据,该数据经过分位数映射偏差校正,基于GFS数据进行校正。校正后数据保持GFS的空间分辨率,但时间分辨率为每日,覆盖2012年至2014年的全年数据。
为了训练KMCast模型以预测哥伦比亚北部地区的风,选取了六个与风预报最相关的气象变量:位势高度、相对湿度、温度、大气压力,以及风矢量的东西向和南北向分量。这些变量在不同的垂直层面上组成共计14个输入通道。具体细节见下表。
| Variable | Selected Layers |
|---|---|
| Zonal/Meridional Wind | 10m above ground, 500hPa, 200hPa |
| Temperature | 2m above ground, 925hPa, 850hPa, 700hPa, 500hPa |
| Geopotential Height | 850hPa |
| Relative Humidity | 2m above ground |
| Pressure | Surface |
NCEP全球预报系统(GFS)分析资料和预报数据可在 https://rda.ucar.edu/datasets/d084006/ 获取。
3.2 WRF配置¶
我们选择哥伦比亚北部地区和中国大陆作为目标区域,利用WRF模型对粗分辨率的GFS数据进行动态降尺度,生成高分辨率数据集。该数据集具有15分钟的时间分辨率和3公里的空间分辨率,采用WRF-ARW V4.5模型系统进行模拟。
哥伦比亚地区的地理范围为北纬8°至14°,西经79.5°至72.5°;中国地区则定义在北纬27°至34°,东经117°至125°。为了实现3公里的模拟精度,采用两层嵌套域结构。两个域都采用兰伯特等角投影。
在中国区域,父域分辨率为9公里,网格点为309×269;嵌套子域的分辨率为3公里,网格点为787×697。哥伦比亚区域的父域网格为173×130,嵌套区域为319×238。
在垂直方向上,两个域均包含34个sigma层,模型顶部设置在50hPa。哥伦比亚北部区域的WRF模拟每天在UTC 0000时启动,覆盖2020年1月至6月以及2021年和2022年的全年。中国大陆区域的模拟也在每天UTC 0000时启动,覆盖2022年全年度。
4 模型代码说明¶
conf/kmcast.yaml:配置文件,定义模型运行的参数和设置,用于控制模型的行为和参数配置。core/metrics.py:性能指标计算模块,用于评估模型的预测效果。data/LRHR_dataset.py:定义数据集加载与预处理流程的脚本。model/sr3_modules:包含模型中的核心模块和子模型。diffusion.py:扩散模型相关代码。unet.py:U-Net结构实现,用于图像处理。model/base_model.py:定义模型的基础结构和框架。model/model.py:模型的主定义文件。model/netsworks.py:网络结构定义。kmcast.py:主执行脚本,整合模型运行、训练和预测流程。
5 结果展示¶
如图所示,左侧为KMCast模型预测结果,中间为观测到的真实风场数据,右侧为输入的低分辨率GFS数据。

如图所示,KMCast模型在哥伦比亚北部预测结果与观测到的风场数据高度一致,验证了其在不同地理区域和气候条件下的泛化能力。
6 参考资料¶
- Fast, High Resolution Wind Information for Operations and Planning via Generative Downscaling