# Copyright (c) 2025 PaddlePaddle Authors. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
NOTE: Code below is reproduced from https://github.com/sifanexisted/fundiff with paddle backend
"""
from __future__ import annotations
from os import path as osp
from typing import Dict
import hydra
import matplotlib.pyplot as plt
import numpy as np
import paddle
from matplotlib import gridspec
from model import FAE
from model import Decoder
from model import DiT
from model import Encoder
from omegaconf import DictConfig
from paddle import nn
from tqdm import tqdm
import ppsci
from ppsci.data.dataset.tmtdataset import BatchParser
from ppsci.utils import save_load
from ppsci.utils.misc import logger
dtype = paddle.get_default_dtype()
class ModelWrapper(nn.Layer):
def __init__(self, encoder: Encoder, decoder: Decoder, dit: DiT):
super().__init__()
self.encoder = encoder
self.decoder = decoder # need to be wrapped for convenience when loading encoder&decoder&dit params togather in inference
self.dit = dit
def forward(self, batch: Dict[str, paddle.Tensor]):
# define the forward pass for diffusion training process
# just ignore the non-training branch code
with paddle.no_grad():
# data in batch have been downsampled already
u = batch["u"]
v = batch["v"]
z_u = self.encoder(u)
z_v = self.encoder(v)
z_c = paddle.concat([z_u, z_v], axis=-1)
if self.training:
p = batch["p"]
sdf = batch["sdf"]
z_p = self.encoder(p)
z_sdf = self.encoder(sdf)
z_1 = paddle.concat([z_p, z_sdf], axis=-1)
z_0 = paddle.randn(z_1.shape) # (b, 200, 512)
t = paddle.uniform(
[z_1.shape[0], *[1 for _ in range(z_1.ndim - 1)]],
min=0.0,
max=1.0,
)
z_t = t * (z_1 - z_0) + z_0
v_t = z_1 - z_0
else:
raise
# only training dit
v_t_pred = self.dit(z_t, t.flatten(), z_c)
if self.training:
return {
"v_t_err": v_t - v_t_pred,
}
else:
raise
def train_fae(cfg: DictConfig):
# Initialize model
encoder = Encoder(**cfg.FAE.encoder)
decoder = Decoder(**cfg.FAE.decoder)
fae = FAE(
cfg.FAE.input_keys,
cfg.FAE.output_keys,
encoder,
decoder,
)
# init constraint
train_dataloader_cfg = {
"dataset": {
"name": "TMTDataset",
"input_keys": cfg.FAE.input_keys,
"label_keys": cfg.FAE.output_keys,
"data_path": cfg.DATA_PATH,
"num_train": cfg.num_train,
"mode": "train",
"stage": cfg.stage,
},
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
"batch_size": cfg.TRAIN.batch_size,
"num_workers": 0,
}
sup_cst = ppsci.constraint.SupervisedConstraint(
train_dataloader_cfg,
loss=ppsci.loss.MSELoss(),
)
# NOTE: A hacky way to plug the batch parser into the constraint.
sample_batch = next(iter(sup_cst.data_loader))
_, h, w, _ = sample_batch.shape
class PostProcessDataLoader:
def __init__(self, dataloader, parser: BatchParser):
self.dataloader = dataloader
self.parser = parser
def __iter__(self):
for batch in self.dataloader:
yield self.parser.random_query(batch)
def __len__(self):
return len(self.dataloader)
sup_cst.data_loader = PostProcessDataLoader(
sup_cst.data_loader,
BatchParser(
cfg.FAE.input_keys,
cfg.FAE.output_keys,
cfg.TRAIN.num_queries,
h,
w,
cfg.TRAIN.solution,
),
)
sup_cst.data_iter = iter(sup_cst.data_loader)
# reset epochs & iters_per_epoch
cfg.TRAIN.iters_per_epoch = len(sup_cst.data_loader)
logger.debug(f"cfg.TRAIN.iters_per_epoch = {cfg.TRAIN.iters_per_epoch}")
cfg.TRAIN.epochs = cfg.TRAIN.steps // cfg.TRAIN.iters_per_epoch
cfg.TRAIN.lr_scheduler.warmup_epoch /= cfg.TRAIN.iters_per_epoch
logger.debug(
f"cfg.TRAIN.lr_scheduler.warmup_epoch = {cfg.TRAIN.lr_scheduler.warmup_epoch}"
)
# Create learning rate schedule and optimizer
lr = ppsci.optimizer.lr_scheduler.ExponentialDecay(
epochs=cfg.TRAIN.epochs,
iters_per_epoch=cfg.TRAIN.iters_per_epoch,
**cfg.TRAIN.lr_scheduler,
)()
optimizer = ppsci.optimizer.AdamW(
lr,
beta1=cfg.TRAIN.beta1,
beta2=cfg.TRAIN.beta2,
epsilon=cfg.TRAIN.eps,
weight_decay=cfg.TRAIN.weight_decay,
grad_clip=nn.ClipGradByGlobalNorm(cfg.TRAIN.clip_norm),
)(fae)
# init solver
solver = ppsci.solver.Solver(
fae,
{"sup": sup_cst},
optimizer=optimizer,
cfg=cfg,
)
# train
solver.train()
def train_diffusion(cfg: DictConfig):
# Initialize fae model
encoder = Encoder(**cfg.FAE.encoder)
decoder = Decoder(**cfg.FAE.decoder)
fae = FAE(
cfg.FAE.input_keys,
cfg.FAE.output_keys,
encoder,
decoder,
)
# Load pretrained fae params and freeze fae
save_load.load_pretrain(
fae,
cfg.FAE.pretrained_model_path,
)
fae.freeze()
# Initialize dit and wrap encoder&decoder&dit into one model for convenience
dit = DiT(**cfg.DIT)
model = ModelWrapper(
encoder,
decoder,
dit,
)
# init constraint
train_dataloader_cfg = {
"dataset": {
"name": "TMTDataset",
"input_keys": cfg.FAE.input_keys,
"label_keys": cfg.FAE.output_keys,
"data_path": cfg.DATA_PATH,
"num_train": cfg.num_train,
"mode": "train",
"stage": cfg.stage,
},
"sampler": {
"name": "BatchSampler",
"drop_last": False,
"shuffle": True,
},
"batch_size": cfg.TRAIN.batch_size,
}
sup_cst = ppsci.constraint.SupervisedConstraint(
train_dataloader_cfg,
loss=ppsci.loss.FunctionalLoss(
lambda inp, label, weight: {"v_t": (inp["v_t_err"] ** 2).mean()}
),
)
# NOTE: A hacky way to plug the batch parser into the constraint.
sample_batch = next(iter(sup_cst.data_loader))
_, h, w, _ = sample_batch.shape
class PostProcessDataLoader:
def __init__(self, dataloader, parser: BatchParser):
self.dataloader = dataloader
self.parser = parser
def __iter__(self):
for batch in self.dataloader:
yield self.parser.random_downsample(batch)
def __len__(self):
return len(self.dataloader)
sup_cst.data_loader = PostProcessDataLoader(
sup_cst.data_loader,
BatchParser(
cfg.FAE.input_keys,
cfg.FAE.output_keys,
None,
h,
w,
cfg.TRAIN.solution,
),
)
sup_cst.data_iter = iter(sup_cst.data_loader)
# reset epochs & iters_per_epoch
cfg.TRAIN.iters_per_epoch = len(sup_cst.data_loader)
logger.debug(f"cfg.TRAIN.iters_per_epoch = {cfg.TRAIN.iters_per_epoch}")
cfg.TRAIN.epochs = cfg.TRAIN.steps // cfg.TRAIN.iters_per_epoch
cfg.TRAIN.lr_scheduler.warmup_epoch /= cfg.TRAIN.iters_per_epoch
logger.debug(
f"cfg.TRAIN.lr_scheduler.warmup_epoch = {cfg.TRAIN.lr_scheduler.warmup_epoch}"
)
# Create learning rate schedule and optimizer
lr = ppsci.optimizer.lr_scheduler.ExponentialDecay(
epochs=cfg.TRAIN.epochs,
iters_per_epoch=cfg.TRAIN.iters_per_epoch,
**cfg.TRAIN.lr_scheduler,
)()
optimizer = ppsci.optimizer.AdamW(
lr,
beta1=cfg.TRAIN.beta1,
beta2=cfg.TRAIN.beta2,
epsilon=cfg.TRAIN.eps,
weight_decay=cfg.TRAIN.weight_decay,
grad_clip=nn.ClipGradByGlobalNorm(cfg.TRAIN.clip_norm),
)(dit)
# init solver
solver = ppsci.solver.Solver(
model,
{"sup": sup_cst},
optimizer=optimizer,
cfg=cfg,
)
# train
solver.train()
@paddle.no_grad()
def evaluate(cfg: DictConfig):
# Initialize encoder & decoder & dit model
encoder = Encoder(**cfg.FAE.encoder)
decoder = Decoder(**cfg.FAE.decoder)
dit = DiT(**cfg.DIT)
# wrap encoder&decoder&dit into one model for convenience
model = ModelWrapper(
encoder,
decoder,
dit,
)
save_load.load_pretrain(model, cfg.EVAL.pretrained_model_path)
# init evaluate data
eval_dataset = ppsci.data.dataset.TMTDataset(
input_keys=cfg.FAE.input_keys,
label_keys=cfg.FAE.output_keys,
data_path=cfg.DATA_PATH,
num_train=cfg.num_train,
mode="test",
stage=cfg.stage,
)
eval_loader = paddle.io.DataLoader(eval_dataset, batch_size=cfg.EVAL.batch_size)
h, w = 200, 100
x_coords = np.linspace(0, 1, h, dtype=dtype)
y_coords = np.linspace(0, 1, w, dtype=dtype)
x_coords, y_coords = np.meshgrid(x_coords, y_coords, indexing="ij")
coords = np.hstack([x_coords.reshape(-1, 1), y_coords.reshape(-1, 1)], dtype=dtype)[
None, ...
]
noise_level = 0.1
d = 1
u_input_list = []
v_input_list = []
p_pred_list = []
sdf_pred_list = []
p_true_list = []
sdf_true_list = []
def sample_ode(
z0: paddle.Tensor = None,
c: paddle.Tensor = None,
num_steps: int = None,
use_conditioning: bool = False,
) -> paddle.Tensor:
dt = 1 / num_steps
traj = [z0]
z = z0
for i in tqdm(range(num_steps)):
t = paddle.ones([z.shape[0]]) * i / num_steps
if use_conditioning:
pred = dit(z, t, c)
else:
pred = dit(z, t)
z = z + pred * dt
traj.append(z)
return z, traj
for batch in tqdm(eval_loader):
u: paddle.Tensor = batch[:, ::d, ::d, 0:1]
v: paddle.Tensor = batch[:, ::d, ::d, 1:2]
p: paddle.Tensor = batch[..., 2:3]
sdf: paddle.Tensor = batch[..., 3:4]
# add noise to input field
u = u + noise_level * paddle.randn(u.shape)
v = v + noise_level * paddle.randn(v.shape)
# compute condition latent code from given field
z_u = encoder(u)
z_v = encoder(v)
z_c = paddle.concat([z_u, z_v], axis=-1) # (b, l, 2c)
# random sample z0 from standard normal distribution
z0 = paddle.randn(shape=z_c.shape)
# integrate ODE
z1_new, _ = sample_ode(
z0=z0,
c=z_c,
num_steps=cfg.EVAL.num_steps,
use_conditioning=cfg.EVAL.use_conditioning,
)
# decode latent code to output field
c_dim = z_c.shape[-1]
z_p_new = z1_new[..., : c_dim // 2]
z_sdf_new = z1_new[..., c_dim // 2 :]
p_pred = decoder(z_p_new, coords)
sdf_pred = decoder(z_sdf_new, coords)
p_pred = p_pred.reshape([-1, h, w])
sdf_pred = sdf_pred.reshape([-1, h, w])
u_input_list.append(u)
v_input_list.append(v)
p_pred_list.append(p_pred)
sdf_pred_list.append(sdf_pred)
p_true_list.append(p)
sdf_true_list.append(sdf)
# Concatenate all results
u_input = paddle.concat(u_input_list, axis=0).squeeze()
v_input = paddle.concat(v_input_list, axis=0).squeeze()
p_pred = paddle.concat(p_pred_list, axis=0)
sdf_pred = paddle.concat(sdf_pred_list, axis=0)
p_true = paddle.concat(p_true_list, axis=0).squeeze()
sdf_true = paddle.concat(sdf_true_list, axis=0).squeeze()
def compute_error(pred, y):
return paddle.linalg.norm(
pred.flatten(1) - y.flatten(1), axis=1, p="fro"
) / paddle.linalg.norm(y.flatten(1), axis=1, p="fro")
# Compute errors
error = compute_error(p_pred, p_true)
logger.info(f"Mean relative p error: {paddle.mean(error).item():.4f}")
logger.info(f"Max relative p error: {paddle.max(error).item():.4f}")
logger.info(f"Min relative p error: {paddle.min(error).item():.4f}")
logger.info(f"Std relative p error: {paddle.std(error, unbiased=True).item():.4f}")
error = compute_error(sdf_pred, sdf_true)
logger.info(f"Mean relative sdf error: {paddle.mean(error).item():.4f}")
logger.info(f"Max relative sdf error: {paddle.max(error).item():.4f}")
logger.info(f"Min relative sdf error: {paddle.min(error).item():.4f}")
logger.info(
f"Std relative sdf error: {paddle.std(error, unbiased=True).item():.4f}"
)
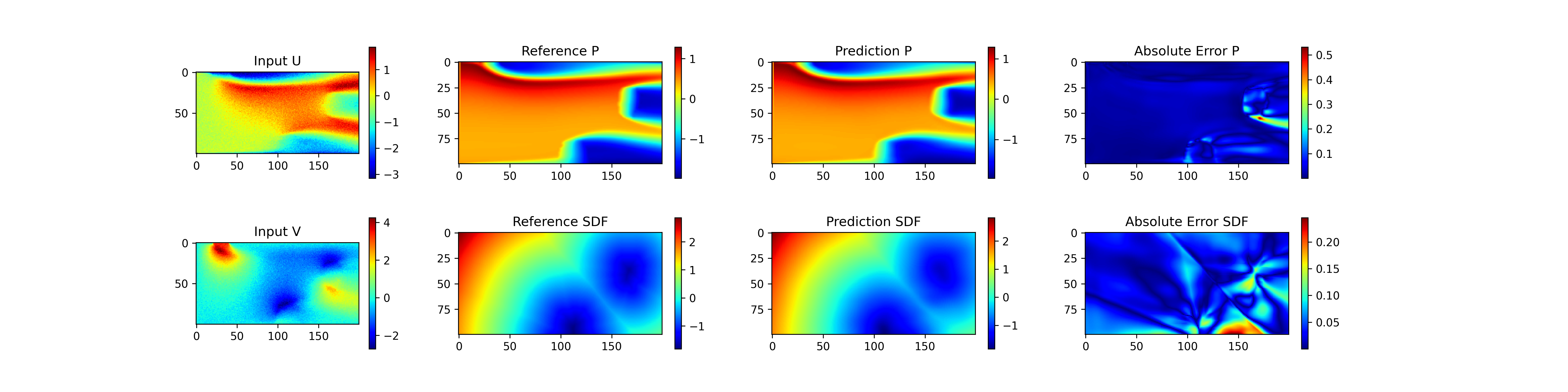
for k in range(u_input.shape[0]):
if k >= 4:
break
fig = plt.figure(figsize=(20, 5))
gs = gridspec.GridSpec(
2, 5, width_ratios=[0.8, 1, 1, 1, 0.05], wspace=0.3, hspace=0.3
)
ax_input_u = fig.add_subplot(gs[0, 0])
ax_input_u.set_title("Input U")
im = ax_input_u.imshow(u_input[k].T, cmap="jet")
plt.colorbar(im, ax=ax_input_u)
ax_input_v = fig.add_subplot(gs[1, 0])
ax_input_v.set_title("Input V")
im = ax_input_v.imshow(v_input[k].T, cmap="jet")
plt.colorbar(im, ax=ax_input_v)
# Reference / Prediction / Error of P
ax_ref = fig.add_subplot(gs[0, 1])
ax_ref.set_title("Reference P")
im = ax_ref.imshow(p_true[k].T, cmap="jet")
plt.colorbar(im, ax=ax_ref)
ax_pred = fig.add_subplot(gs[0, 2])
ax_pred.set_title("Prediction P")
im = ax_pred.imshow(p_pred[k].T, cmap="jet")
plt.colorbar(im, ax=ax_pred)
ax_err = fig.add_subplot(gs[0, 3])
ax_err.set_title("Absolute Error P")
im = ax_err.imshow(paddle.abs(p_pred[k].T - p_true[k].T), cmap="jet")
plt.colorbar(im, ax=ax_err)
# Reference / Prediction / Error of SDF
ax_ref2 = fig.add_subplot(gs[1, 1])
ax_ref2.set_title("Reference SDF")
im = ax_ref2.imshow(sdf_true[k].T, cmap="jet")
plt.colorbar(im, ax=ax_ref2)
ax_pred2 = fig.add_subplot(gs[1, 2])
ax_pred2.set_title("Prediction SDF")
im = ax_pred2.imshow(sdf_pred[k].T, cmap="jet")
plt.colorbar(im, ax=ax_pred2)
ax_err2 = fig.add_subplot(gs[1, 3])
ax_err2.set_title("Absolute Error SDF")
im = ax_err2.imshow(paddle.abs(sdf_pred[k].T - sdf_true[k].T), cmap="jet")
plt.colorbar(im, ax=ax_err2)
plt.tight_layout()
plt.savefig(osp.join(cfg.output_dir, f"result_of_sample_{k}.png"), dpi=300)
plt.close()
def export(cfg: DictConfig):
raise NotImplementedError
def inference(cfg: DictConfig):
raise NotImplementedError
@hydra.main(version_base=None, config_path="./conf", config_name="fae.yaml")
def main(cfg: DictConfig):
if cfg.mode == "train":
if cfg.stage == "fae":
train_fae(cfg)
elif cfg.stage == "dit":
train_diffusion(cfg)
else:
raise ValueError(
f"cfg.stage should be 'fea', or 'dit', but got {cfg.stage}"
)
elif cfg.mode == "eval":
evaluate(cfg)
elif cfg.mode == "export":
export(cfg)
elif cfg.mode == "infer":
inference(cfg)
else:
raise ValueError(
f"cfg.mode should in ['train', 'eval', 'export', 'infer'], but got '{cfg.mode}'"
)
if __name__ == "__main__":
main()