隐空间神经算子LatentNO(or LNO)¶
# Darcy
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Darcy_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Darcy_$f.npy --create-dirs -o ./datas/Darcy_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Darcy.yaml
# Elasticity
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Elasticity_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Elasticity_$f.npy --create-dirs -o ./datas/Elasticity_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Elasticity.yaml
# Pipe
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Pipe_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Pipe_$f.npy --create-dirs -o ./datas/Pipe_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Pipe.yaml
# NS2d
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/NS2d_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/NS2d_$f.npy --create-dirs -o ./datas/Pipe_$f.npy}
python LatentNO-time.py --config-name=LatentNO-NS2d.yaml
# Darcy
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Darcy_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Darcy_$f.npy --create-dirs -o ./datas/Darcy_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Darcy.yaml mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/LatentNO/LatentNO_Darcy_pretrained.pdparams
# Elasticity
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Elasticity_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Elasticity_$f.npy --create-dirs -o ./datas/Elasticity_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Elasticity.yaml mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/LatentNO/LatentNO_Elasticity_pretrained.pdparams
# Pipe
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Pipe_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/Pipe_$f.npy --create-dirs -o ./datas/Pipe_$f.npy}
python LatentNO-steady.py --config-name=LatentNO-Pipe.yaml mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/LatentNO/LatentNO_Pipe_pretrained.pdparams
# NS2d
# linux
wget -c -P ./datas/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/NS2d_{train,val}.npy
# windows
# foreach ($f in "train","val") {curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/LatentNO/NS2d_$f.npy --create-dirs -o ./datas/Pipe_$f.npy}
python LatentNO-time.py --config-name=LatentNO-NS2d.yaml mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/LatentNO/LatentNO_NS2d_pretrained.pdparams
1. 背景简介¶
偏微分方程(PDE)的求解的正问题指的是在已知方程的具体形式和初始、边界条件的情况下求出解函数。可以被统一为算子学习的任务,从而被归纳为序列到序列的转换框架。神经算子模型可以基于成对训练数据,通过数据驱动的方式学习从输入函数到输出函数的映射,其中输入函数和输出函数均通过采样点序列进行表示。 近年来 Transformer 架构在神经算子的构建中占据了主导地位。注意力机制建模了序列中全体对象之间的长距离非线性相互作用关系,自然地符合 PDE 求解过程中序列到序列的表征方式,并且相较于传统的全连接结构可以提供更精确的建模结果。但是注意力机制相对于序列长度的时间复杂度是平方级别,因此使用注意力机制构建神经算子带来的计算成本急剧增加。为了降低计算成本,一部分已有工作尝试采用线性时间复杂度的注意力机制变体取代原始注意力机制,但是由于其建模能力有限,往往会牺牲 PDE 的求解精度。另一部分已有工作尝试在隐空间中使用少量物理特征求解 PDE,从而摆脱原始几何空间中大量采样点之间错综复杂的相互作用关系,并在紧致的隐空间中捕捉物理特征之间的关联,然而这些方法要么依赖人工指定的基函数特征,要么没能构建持续存在的隐空间。 因此, 本案例提出物理交叉注意力模块,该模块解耦了输入的观测样本和输出的待预测样本的位置,并从数据中自主学习持续存在的隐空间。基于物理交叉注意力模块,进一步设计了隐空间神经算子模型。
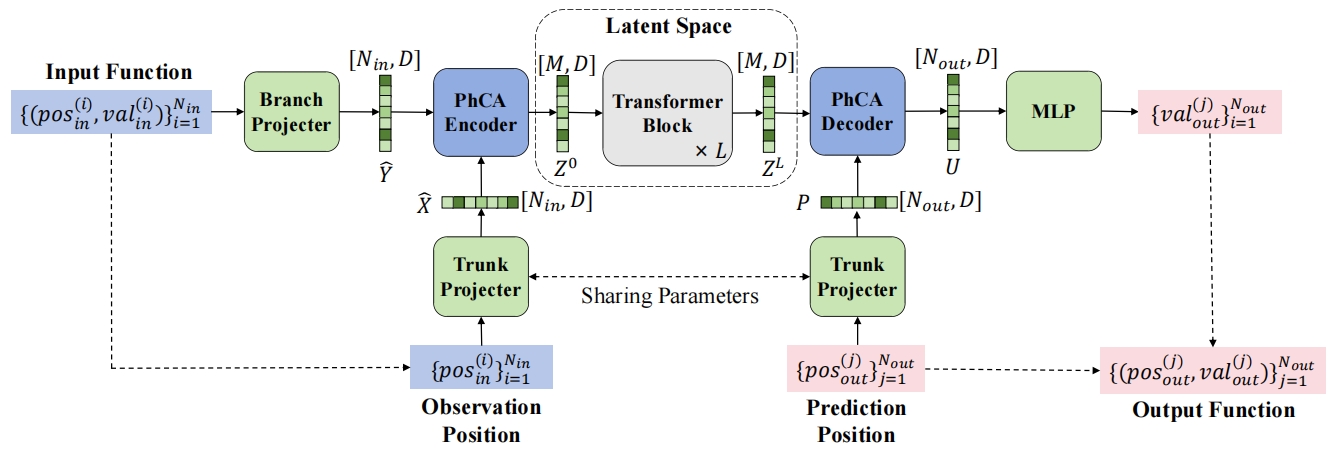
2. 隐空间神经算子的实现¶
本节将讲解如何基于PaddleScience代码,实现对于隐空间神经算子模型的构建、训练、测试和评估。案例的目录结构如下。
LatentNO/
├── config
│ ├── LatentNO-Darcy.yaml
│ └── ...
├── datas
│ ├── Darcy_train.npy
│ ├── Darcy_val.npy
│ └── ...
├── LatentNO-steady.py
├── LatentNO-time.py
└── utils.py
2.1 数据集构建和载入¶
针对本项目中涉及的不同任务,本样例的数据集可以被划分为两类:一类是静态数据(Darcy、Pipe、 Elasticity);另一类含时数据(NS2d)。为了兼容 PaddleScience 框架下的自动训练流程,本案例设计并实现了专用的数据集类,分别对应静态场景与动态场景,命名为 LatentNODataset 与 LatentNODataset_time。接下来首先对 LatentNODataset 的构建做具体说明。
对于静态数据类任务,数据首先以 .npy 文件的形式存放在 ./datas 目录中,每个文件按照数据名称与模式(训练集或验证集)进行命名,例如 Darcy_train.npy 或 Darcy_val.npy。这些文件内部存储了包含 x、y1 与 y2 三个关键变量的字典,x与y1均会被作为模型的输入 ,而 y2 则为最终的预测目标。在载入阶段,数据会被转换为 Paddle 的张量格式,并根据需求调整形状以满足模型的输入要求,并在必要时将 x 与 y1 进行拼接。
为了增强模型的训练稳定性与泛化能力,数据集类中还内置了归一化模块。该模块会在初始化阶段统计各变量的均值与标准差,并在数据载入时自动进行归一化处理。同时提供了反归一化的接口,便于在推理或可视化时还原到物理真实尺度。
| ppsci/data/dataset/latent_no_dataset.py | |
|---|---|
在训练过程中,通过调用 __getitem__ 方法,可以按索引返回一条数据的输入、标签及对应权重,从而无缝衔接到训练管线中。
整个数据以 PaddleScience 约定的格式存储在字典中,input 用于提供输入张量,label 用于提供监督信号,而 weight_dict 则允许用户为不同的损失分量赋予权重。
对于含时数据类任务,数据集的构建是类似的,主要区别在于 LatentNODataset_time 在输入字典中同时保留了 x、y1 与 y2,使得模型能够直接获取到时间相关的上下文信息以辅助训练,而标签部分依旧为 y2,用以监督最终的预测结果。这种设计保证了训练过程对时间依赖特性的捕捉,也为后续的长时间演化预测提供了良好的数据接口。
2.2 模型构建¶
隐空间神经算子包含编码、隐空间算子拟合和解码三个过程。在处理静态数据任务中,模型的前向传播过程用PaddleScience表示如下:
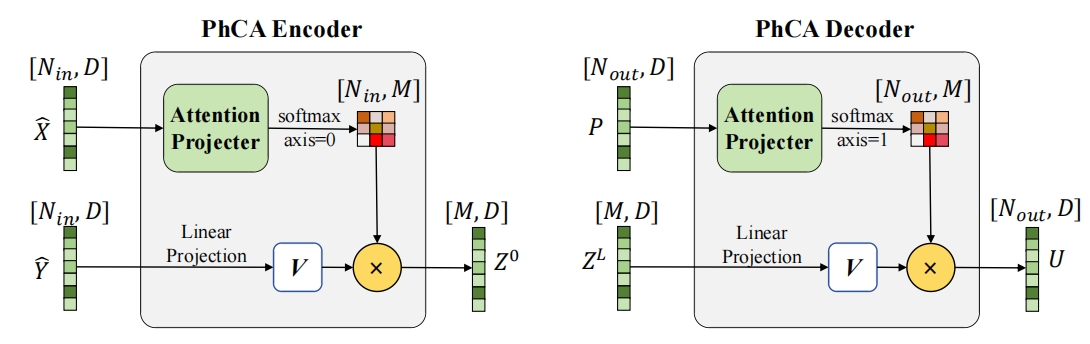
编码过程包含输入投影和输入函数编码两部分。其中输入投影操作将几何空间中以序列形式输入的观测函数的采样位置与对应的物理量值组成的元组提升到更高的向量维度。几何空间是PDE输入或输出的原始空间,其中包含若干个样本点,每个样本由多维空维位置坐标和多维物理量值组成。通过输入投影操作,观测函数能够被投影到更容易捕捉非局部特征的空间中。输入函数编码操作将投影后的输入数据从几何空间映射到隐空间中。隐空间神经算子模型使用隐空间中的假想采样位置的表征Token来对输入函数进行重新表示,其中假想采样位置的数量远小于输入函数在几何空间中的采样点数,实现序列压缩的目的。隐空间神经算子模型使用物理交叉注意力来完成输入函数从几何空间到隐空间的编码操作。编码操作的相关代码用PaddleScience表示如下:
| ppsci/arch/latent_no.py | |
|---|---|
对输入函数完成编码后,待处理的序列长度显著减少为了隐空间中假想采样点位置的数量,因此在隐空间中对输入函数的特征进行提取和转换比在原本几何空间中更加高效。隐空间神经算子模型在隐空间中拟合PDE问题的解算子,使用堆叠的 Transformer 层,借助自注意力机制作为核积分算子,每一层都在隐空间中将假想采样位置上的表征 Token 进行信息聚合,从而将输入函数的特征转换为输出函数的特征。在隐空间中基于更短的特征序列进行解算子的拟合赋予了隐空间神经算子模型在 PDE 问题上更高的求解效率,并且同时兼容了更强建模能力的核积分算子,从而也确保了在 PDE 问题上出色的求解精度。隐空间中的堆叠结构用PaddleScience表示如下:
| ppsci/arch/latent_no.py | |
|---|---|
解码过程包含输出函数解码和输出投影两部分。输出函数解码操作将经过堆叠 Transformer 层转换后的假想采样位置上的表征 Token 映射回几何空间中。隐空间神经算子模型再次使用物理交叉注意力,根据输出函数的查询位置解码隐空间中输出函数表征序列在对应待预测位置上的表征向量。输出投影操作则将解码得到的待预测位置上的表征向量投影为预测的低维度物理量值。解码过程相关代码用PaddleScience表示如下
| ppsci/arch/latent_no.py | |
|---|---|
在处理含时数据时,模型整体结构不变,但为了满足PaddleScience自动训练的要求,LatentNO_time 类重写了前向传播函数,实现了一个时间展开(time-unroll / 自回归)流程。在时间迭代内部,LatentNO_time 引入了两条不同的下一步输入来源:训练期间额外使用外部提供的 y2(标签信息),从 y2 中切出对齐的片段 y2[..., t:t+step] 作为下一个输入一部分;在推断时则使用模型的 pred_step 作为下一个输入并对其执行 stop_gradient=True,以阻断跨步的梯度传播。无论采用哪种来源,下一步的 current_y 都通过“保留 trunk 部分 + 丢弃最早的若干时间槽 + 在末尾拼接新片段”的滑动窗口方式更新。用 PaddleScience 表示如下
在训练或验证函数中,模型通过如下代码进行实例化。
| examples/LatentNO/LatentNO-steady.py | |
|---|---|
| examples/LatentNO/LatentNO-time.py | |
|---|---|
2.3 约束构建¶
本案例采用监督学习,按照 PaddleScience 的API结构说明,采用内置的 SupervisedConstraint 构建监督约束。用 PaddleScience 代码表示如下(测试约束类似,区别在于部分任务中需要在计算测试损失时进行反归一化操作,即通过 sup_constraint.data_loader.dataset.normalizer 获得训练集的归一化器并作为参数传入 RelLpLoss)
其中损失函数为相对 Lp 损失。对于静态任务,损失函数 RelLpLoss 表示如下。
同样,对于含时任务做出了适应自动训练框架的调整,RelLpLoss_time 通过 use_full_sequence 参数实现使用逐时间步累积误差进行梯度反传更新,并使用完整序列一次性误差作为评估指标。
2.4 优化器构建¶
训练器采用AdamW优化器,学习率设置由配置文件给出,并使用OneCycleLR控制学习率变化。用 PaddleScience 代码表示如下
2.5 模型训练¶
完成上述设置之后,只需要将上述实例化的对象按顺序传递给ppsci.solver.Solver,然后启动训练即可。用PaddleScience 代码表示如下
| examples/LatentNO/LatentNO-steady.py | |
|---|---|
3. 完整代码¶
| examples/LatentNO/LatentNO-steady.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 | |
4. 结果展示¶
以下展示隐空间神经算子在若干PDE前向问题中的性能表现。

5. 参考文献¶
[1] Wang T, Wang C. Latent neural operator for solving forward and inverse pde problems[J]. Advances in Neural Information Processing Systems, 2024, 37: 33085-33107.