2D-LDC(2D Lid Driven Cavity Flow)¶
# linux
wget -c -P ./data/ \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re100.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re400.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re100.mat --create-dirs -o ./data/ldc_Re100.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re400.mat --create-dirs -o ./data/ldc_Re400.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat --create-dirs -o ./data/ldc_Re1000.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat --create-dirs -o ./data/ldc_Re3200.mat
python ldc_2d_Re3200_sota.py
# linux
wget -c -P ./data/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat --create-dirs -o ./data/ldc_Re1000.mat
python ldc_2d_Re3200_sota.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/ldc/ldc_re1000_sota_pretrained.pdparams
| Pretrained Model | \(Re\) | Metrics |
|---|---|---|
| - | 100 | U_validator/loss: 0.00017 U_validator/L2Rel.U: 0.04875 |
| - | 400 | U_validator/loss: 0.00047 U_validator/L2Rel.U: 0.07554 |
| ldc_re1000_sota_pretrained.pdparams | 1000 | U_validator/loss: 0.00053 U_validator/L2Rel.U: 0.07777 |
| - | 3200 | U_validator/loss: 0.00227 U_validator/L2Rel.U: 0.15440 |
# linux
wget -c -P ./data/ \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re100.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re400.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1600.mat \
https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re100.mat --create-dirs -o ./data/ldc_Re100.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re400.mat --create-dirs -o ./data/ldc_Re400.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1000.mat --create-dirs -o ./data/ldc_Re1000.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re1600.mat --create-dirs -o ./data/ldc_Re1600.mat
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat --create-dirs -o ./data/ldc_Re3200.mat
python ldc_2d_Re3200_piratenet.py
# linux
wget -c -P ./data/ https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat
# windows
# curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/ldc/ldc_Re3200.mat --create-dirs -o ./data/ldc_Re3200.mat
python ldc_2d_Re3200_piratenet.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/ldc/ldc_re3200_piratenet_pretrained.pdparams
| Pretrained Model | \(Re\) | Metrics |
|---|---|---|
| - | 100 | U_validator/loss: 0.00016 U_validator/L2Rel.U: 0.04741 |
| - | 400 | U_validator/loss: 0.00071 U_validator/L2Rel.U: 0.09288 |
| - | 1000 | U_validator/loss: 0.00191 U_validator/L2Rel.U: 0.14797 |
| - | 1600 | U_validator/loss: 0.00276 U_validator/L2Rel.U: 0.17360 |
| ldc_re3200_piratenet_pretrained.pdparams | 3200 | U_validator/loss: 0.00016 U_validator/L2Rel.U: 0.04166 |
Note
This case only provides pre-trained models under \(Re=1000/3200\). If you need pre-trained models under other Reynolds numbers, please execute the training command manually to train and obtain model weights under each Reynolds number.
1. Background Introduction¶
The 2D Lid Driven Cavity Flow (LDC) problem is applied in many fields. For example, this problem can be used to verify the validity of calculation methods in the field of computational fluid dynamics (CFD). Although the boundary conditions of this problem are relatively simple, its flow characteristics are very complex. In the lid-driven flow LDC, the top wall moves in the x-direction at a speed of U=1, while the other three walls are defined as no-slip boundary conditions, that is, the speed is zero.
In addition, the LDC problem is also used to study and predict flow phenomena in aerodynamics. For example, in the automotive industry, simulating and analyzing the air flow inside the car body can help optimize the design and performance of the vehicle.
In general, the LDC problem has been widely used in computational fluid dynamics, aerodynamics and related fields, and has played an important role in studying and predicting flow phenomena and optimizing product design.
2. Problem Definition¶
This case assumes \(Re=3200\), the calculation domain is a square cavity with length and width both being 1, and the following formula is applied to study the steady flow field problem of lid-driven cavity flow:
Mass conservation:
\(x\) momentum conservation:
\(y\) momentum conservation:
Let:
\(t^* = \dfrac{L}{U_0}\)
\(x^*=y^* = L\)
\(u^*=v^* = U_0\)
\(p^* = \rho {U_0}^2\)
Define:
Dimensionless coordinate \(x: X = \dfrac{x}{x^*}\); Dimensionless coordinate \(y: Y = \dfrac{y}{y^*}\)
Dimensionless velocity \(x: U = \dfrac{u}{u^*}\); Dimensionless velocity \(y: V = \dfrac{v}{u^*}\)
Dimensionless pressure \(P = \dfrac{p}{p^*}\)
Reynolds number \(Re = \dfrac{L U_0}{\nu}\)
Then the following dimensionless Navier-Stokes equation can be obtained, applied inside the cavity:
Mass conservation:
\(x\) momentum conservation:
\(y\) momentum conservation:
For the cavity boundary, Dirichlet boundary conditions need to be imposed:
Upper boundary:
Left boundary, lower boundary, right boundary:
3. Problem Solving¶
Next, we will explain how to convert the problem into PaddleScience code step by step and solve the problem using deep learning methods. In order to quickly understand PaddleScience, only key steps such as model construction, equation construction, and computational domain construction are described below, while other details please refer to API Documentation.
3.1 Model Construction¶
In the 2D-LDC problem, each known coordinate point \((x, y)\) has its own lateral velocity \(u\), longitudinal velocity \(v\), and pressure \(p\) Three unknown quantities to be solved. Here we use PirateNet suitable for PINN tasks to represent the mapping function \(f: \mathbb{R}^2 \to \mathbb{R}^3\) from \((x, y)\) to \((u, v, p)\), i.e.:
In the above formula, \(f\) is the PirateNet model itself, expressed in PaddleScience code as follows
The cfg.MODEL configuration is as follows:
In order to accurately and quickly access the value of a specific variable during calculation, we specify here that the input variable name of the network model is ["x", "y"] and the output variable name is ["u", "v", "p"]. These names are consistent with the subsequent code.
As shown above, by specifying the number of layers, number of neurons, and activation function of PirateNet, we instantiate a neural network model model with 12 layers of hidden neurons, 256 neurons per layer, using "tanh" as the activation function.
3.2 Curriculum Learning¶
To speed up convergence, we use the Curriculum learning method to train the model, that is, first train the model at a low Reynolds number, then gradually increase the Reynolds number, and finally reach convergence at a high Reynolds number.
3.3 Equation Construction¶
Since 2D-LDC uses the 2D steady-state form of the Navier-Stokes equation, NavierStokes built into PaddleScience can be used directly.
In the curriculum learning function, we need to specify the necessary parameters when instantiating the NavierStokes class: dynamic viscosity \(\nu=\frac{1}{Re}\), fluid density \(\rho=1.0\), where \(Re\) is a variable that will gradually increase during the training process.
3.4 Computational Domain Construction¶
The data required for the training and evaluation of the 2D-LDC problem in this article is obtained by reading the file corresponding to the Reynolds number.
3.5 Constraint Construction¶
According to the dimensionless formula and boundary conditions obtained in 2. Problem Definition, corresponding to two constraints guiding model training in the computational domain, namely:
-
Dimensionless Navier-Stokes equation constraint imposed on internal points of the rectangle (after simple term shifting)
\[ \dfrac{\partial U}{\partial X} + \dfrac{\partial U}{\partial Y} = 0 \]\[ U\dfrac{\partial U}{\partial X} + V\dfrac{\partial U}{\partial Y} + \dfrac{\partial P}{\partial X} - \dfrac{1}{Re}(\dfrac{\partial ^2 U}{\partial X^2} + \dfrac{\partial ^2 U}{\partial Y^2}) = 0 \]\[ U\dfrac{\partial V}{\partial X} + V\dfrac{\partial V}{\partial Y} + \dfrac{\partial P}{\partial Y} - \dfrac{1}{Re}(\dfrac{\partial ^2 V}{\partial X^2} + \dfrac{\partial ^2 V}{\partial Y^2}) = 0 \]In order to facilitate obtaining intermediate variables, the
NavierStokesclass internally names the results on the left side of the above equation ascontinuity,momentum_x,momentum_y. -
Dirichlet boundary condition constraints imposed on the upper, lower, left, and right boundaries of the rectangle
Upper boundary:
\[ u(x, y) = 1 − \dfrac{\cosh (C_0(x − 0.5))} {\cosh (0.5C_0)} , \]Left boundary, lower boundary, right boundary:
\[ u=0, v=0 \]
Next, use SupervisedConstraint built into PaddleScience to construct the above two constraints.
3.5.1 Interior Point Constraint¶
Taking SupervisedConstraint acting on rectangular internal points as an example, the code is as follows:
The first parameter of SupervisedConstraint is the dataset configuration, used to describe how to construct input data. Here fill in the constructor functions gen_input_batch and gen_label_batch for input data and label data, and the dataset name ContinuousNamedArrayDataset;
The second parameter is the target value of the constraint variable. Here fill in equation["NavierStokes"].equations instantiated in the 3.3 Equation Construction section;
The third parameter is the loss function. Here we choose the commonly used MSE function, and reduction is set to "mean", which means we will average the loss terms generated by all data points participating in calculation;
The fourth parameter is the name of the constraint condition. We need to name each constraint condition for subsequent indexing. Here we name it "PDE".
3.5.2 Boundary Constraint¶
Process the label data of the upper boundary according to the above corresponding formula, and set the label data of other points to 0. Then continue to construct the Dirichlet constraint of the cavity boundary, we still use the SupervisedConstraint class.
After the differential equation constraint, boundary constraint, and initial value constraint are constructed, encapsulate them into a dictionary with the name we just named as the keyword for subsequent access.
3.6 Hyperparameter Setting¶
Next, you need to specify the number of training rounds in the configuration file, training 10, 20, 50, 50, 500 rounds on Re=100, 400, 1000, 1600, 3200 respectively, with 1000 iterations per round.
Secondly, set a suitable learning rate decay strategy,
Finally, set the automatic loss balancing strategy during training to GradNorm,
3.7 Optimizer Construction¶
The training process will call the optimizer to update model parameters. Here, the commonly used Adam optimizer is selected.
3.8 Validator Construction¶
During the training process, the training status of the current model is usually evaluated using the validation set (test set) at a certain round interval, so ppsci.validate.SupervisedValidator is used to construct the validator.
Here calculate the prediction error of \(U=\sqrt{u^2+v^2}\);
Evaluation metric metric select ppsci.metric.L2Rel;
The rest of the configuration is similar to the setting of Constraint Construction.
3.9 Model Training, Evaluation and Visualization¶
After completing the above settings, you only need to pass the instantiated objects to ppsci.solver.Solver in order, and then start training and evaluation.
4. Complete Code¶
| ldc_2d_Re3200_piratenet.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 | |
5. Result Display¶
The following shows the prediction result \(U=\sqrt{u^2+v^2}\) of the model for the internal points of the square computational domain with a side length of 1.
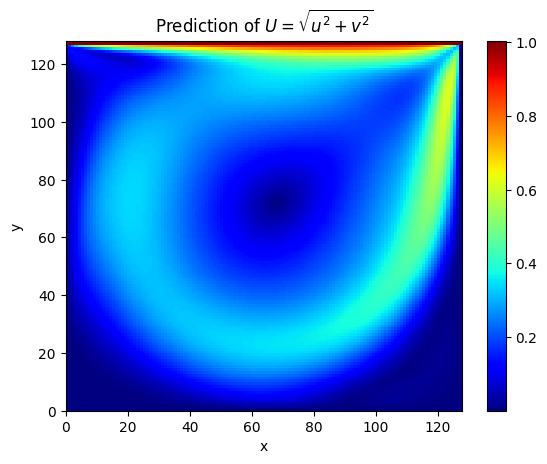
It can be seen that at \(Re=1000\), the prediction result is basically the same as the solver result (L2 relative error is 7.7%).
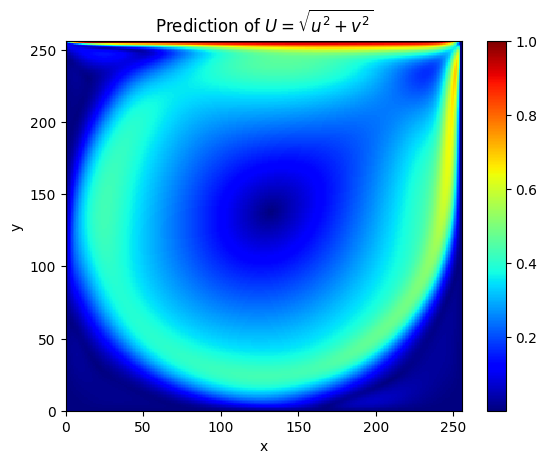
It can be seen that at \(Re=3200\), the prediction result is basically the same as the solver result (L2 relative error is 4.1%).